
2023. 8. 9.ㆍTech
안녕하세요. 케이뱅크 Data-Biz팀에서 데이터 사이언티스트로 일하고 있는 권혁민 입니다.
이 글에서는 당행 앱영역에 적용한 자동화된 개인화 Content 추천시스템 개발 사례에 대해 공유 드리고자 합니다.

추천 시스템은 한정된 앱 영역에 고객별 맞춤형 정보제공을 위한 Information Filter 역할을 하거나, 고객의 앱내 행동에 따른 추가적인 연관 콘텐츠를 보여주어 고객과의 Engagement를 강화하는 역할을 합니다.
추천시스템은 고객의 편의성 및 수익에 긍정적인 영향을 미치는 것에서 더 나아가, 고객들의 선호가 유도되거나 혹은 조작(manipulation)될 수 있는 가능성에 대한 연구도 이루어질 만큼, 그 영향도는 점차 증대되고 있습니다.
※ 참조. 추천을 통해 고객의 의도가 조작될수 있는 연구사례 - https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3346686 , https://www.jstor.org/stable/24700286
Reducing Recommender Systems Biases: An Investigation of Rating Display Designs
54 Pages Posted: 27 Mar 2019 Last revised: 12 Mar 2021 Abstract Prior research has shown that online recommendations have a significant influence on consumers’ preference ratings and economic behavior. Specifically, biases induced by observing personaliz
papers.ssrn.com
홈탭의 상단 화면은 고객이 앱 진입시 가장 먼저 보여지게 되는 페이지로, 고객이 바로 이탈할 것인지, 계속해서 상품 탐색을 이어갈 것인지에 영향을 줄 수 있는 중요한 영역입니다.
위와 같은 이유로 저희 팀에서는 홈 영역에 고객별로 맞춤화된 컨텐츠를 제공한다면 고객의 앱 사용의 편의를 높이고 고객과의 Engagement를 강화시켜 고객의 앱경험에 긍정적인 영향을 줄 것으로 판단했습니다. 하단의 그림은 개인화 알고리즘이 적용된 Contents추천 배너 예시 입니다.
고객에게 맞춤형 배너 추천을 제공하기 위해선, 먼저 각각의 고객들이 어떠한 금융 Needs가 있고, 어떤 서비스를 좋아하는지 선호도 정확하게 예측하는 작업이 필요했습니다.
또한 분석을 통해 나온 예측의 결과가 자동으로 앱에 전달되어 효율적으로 노출이 되어야 하고, 노출된 컨텐츠에 대한 고객반응 데이터가 적절하게 분석DB에 적재되야하는 과제가 있었습니다.
이러한 일련의 프로세스는 MLOps(Machine Learning Operations)라고도 하며, ML모델 개발과 운영을 통합해 자동화된 고객서비스를 제공하는 시스템을 이야기합니다.
금번 article에서는 개인화된 추천서비스를 제공하기 위해시 어떠한 가설과 목표를 가지고 알고리즘을 적용했고, 추천contents를 고객에게 자동으로 Serving하기 까지 시스템을 구축한 경험을 공유하고자 합니다.
추천시스템 모델 개발 Process
당행 추천시스템을 설명하기 위해 다음과 같이 총 3개의 Step으로 나누어 보았습니다.
■ 첫 번째는 후보군 생성(Candidate generate) Step으로 고객별로 추천할 수 있는 후보 상품 및 서비스 카테고리를 구성하는 단계입니다.
후보군 산출 단계에서는 고객이 선호 할만한 관심사가 최대한 담긴 카테고리로 설정하였고, 추천 범위를 최대한 확장하여 Coverage를 높일 수 있도록 하였습니다. 이렇게 구성된 추천 카테고리를 보다 더 세분화하고자, 고객의 최신 행동에 따라 추천카테고리가 달라지고 고객의 행동에 따라 추천컨텐츠가 Refresh될 수 있도록 고객별 노출 및 반응 정보를 추가하여 최종적으로 추천카테고리를 크게 확장했습니다.
①고객이 사용가능한 앱내 상품 및 서비스 카테고리화
② 각 카테고리별 고객의 반응 행동 및 Fatigue정도에 따른 추가 카테고리화
③ 최종 카테고리수 = ①상품/서비스 카테고리수 * ② 노출/반응 카테고리수
■두 번째는 고객선호예측(Customer preference prediction) Step으로 ‘고객의 Demo정보’, ‘과거 계약 및 거래 History’, ‘최신 고객 맥락 행동(Context) 정보’ 에 기반한 클릭 or 계약 등의 다음 행동을 예측하는 단계입니다.
실제 추천모델을 만들기 위해 분석해보면, 고객과 아이템은 굉장히 방대 하면서 동시에 sparse합니다. 그리고 데이터를 수집하여 사용 가능한 형태로 만들고, 다시 모델로 추론하여 고객에 Serving하기까지 상당히 여러 단계를 거쳐야 합니다.
최근엔 Multi-Stage Recommendation system 방식을 추구하는 연구가 많이 이루어지고 있는데, 당행도 마찬가지로 각 단계별로 목표하는 바가 다르기 때문에 추천시스템 모델 개발을 각 단계로 분리하여 각 단계별 목표에 대한 최적화를 할 수 있도록 분석하였습니다.
※ Multi-Stage Recommendation system 관련사례 - https://librerank-community.github.io/
Neural Re-ranking Tutorial (RecSys 22)
Neural Re-ranking Tutorial (RecSys 22) Abstract Re-ranking is one of the most critical stages for multi-stage recommender systems (MRS), which re-orders the input ranking lists by modeling the cross-item interaction. Recent re-ranking methods have evolved
librerank-community.github.io
Multi-Stage Recommendation system 단계별 구현 사례
1) Recall Stage (Pre-ranking — 후보군 설정)
최근 추천시스템 연구에선 추천항목의 정확도 뿐만 아니라 생각지 못한 참신한 추천, 다양한 상품 추천 등이 중요한 요소로 간주되고 있습니다.
※ 참심성, 다양성 추천 관련 사례 : https://dl.acm.org/doi/10.1145/2043932.2043955
Rank and relevance in novelty and diversity metrics for recommender systems | Proceedings of the fifth ACM conference on Recomme
Recommender systems are being used to assist users in finding relevant items from a large set of alternatives in many online applications. However, while most research up to this point has focused on improving the accuracy of recommender systems, other ...
dl.acm.org
본 프로젝트에서도 가장 중요한 가설중의 하나가 바로 Diversity관점의 추천이었습니다. 즉, 고객의 다양한 상품경험의 중요성이었는데요, 다양한 상품에 대한 경험(최종적으로 계약하지 않더라도 단순 노출만의 효과)은 고객의 유지율을 강화시키고 MAU에 직접적인 영향을 미친다는 가설입니다.
① Relevence 측면의 고객의 행동과 연관성이 있는 추천 방식을 고려하였고, 고객-상품과의 연관성을 예측하는 알고리즘을 사용하여 노출항목으로 선정하였습니다.
② Novelty측면의 추천을 위해 고객이 관심은 없고, 직접적인 연관성은 없으나 좋아할만한 새로운 상품을 추천해주는 알고리즘들을 매핑하였습니다. 당행고객중 상품 or 서비스에 대한 관심을 남기는 고객보다, 단순 이체거래만 하는 고객군이 많다보니 해당 알고리즘이 매우 중요했습니다.
③ Serendipity측면의 추천은 예상밖의 추천을 제공하면서 CTR을 최적화하기 위해 MAB(Multi armed bendit)알고리즘을 매핑하여 추천항목을 구성하였습니다.
최종적으로 추천의 목적에 따른 알고리즘을 매핑한 뒤 Merge하여 diversity를 maximize 하도록 알고리즘 조합을 통해 다양한 아이템이 추천군으로 될 수 있도록 Candidate으로 확보하였습니다.
2) Re-ranking (Hybrid Filtering)
위의 단계에서 각각의 알고리즘을 통해 도출된 결과를 기반으로 최종적으로 예측기간동안 해당상품의 클릭 여부 데이터를 통해 next action을 predict 할 수 있도록 했으며, LGBM을 활용하였습니다. 이와 같이 별도의 Re-rank Layer를 가지고 있는 경우, 아이템의 up-Sell 추천보다는 cross-Sell에 집중하여 유저의 Intention(Sequential Action) 기반 boosting을 하는 과정이라고 볼 수 있습니다. 위에서 언급한 것 처럼 이 과정은 후보군 항목의 diversity를 최대화하고, 후보 추천군들의 예측확률을 산출하는데 중요한 단계입니다.
3) Ranking Order 전략수립
최종적으로 고객별로 Top N 카테고리가 결정되었고, 고객별로 몇 개의 배너 (컨텐츠) 를 노출할 것인지 결정하는 단계가 남아있습니다. 고객에게 소수의 아이템을 추천해줄수록 주목도는 높지만 다양성/우연성이 떨어지기 때문에 최종적으로 고객이 홈화면 (개인화 영역)에 평균적으로 어느정도 재유입이 되고 얼마나 노출이 되는지에 따라 노출횟수를 설정했고 총 4개일 경우 고객의 CTR(Click Through Rate : 노출대비클릭)이 가장 효율이 좋았습니다.
■ 세번째 단계는 후처리(Post-Processing Step)입니다. 이번 step은 ML기반 실 서비스에서 가장 중요한 단계라고 생각합니다. 후처리는 추천 모델이 제공한 추천 결과를 보완하여 고객에게 더욱 적합한 추천을 제공하는 과정이라고 보시면 됩니다. 후처리 단계에서 고려해야할 주요 issue를 3가지 Point로 정리해 봤습니다.
1) Domain Knowledge
대부분의 실서비스에서는 ML에의해 계산된 랭킹값에 더해서 비즈니스 로직 or 도메인 지식이 결합이 되야 합니다. 당행 고객은 대부분이 여신/수신상품 계약이나 입출금을 목적으로 유입되다 보니 비이자수익을 담당하는 제휴 상품의 노출이 중립적인 ML기반으로는 상대적으로 노출이 적어지게 됩니다. Long-tail카테고리 즉 비인기 카테고리에 대해 가중치를 두어서 노출량을 늘릴 수 있고, 별도의 logic이 추가되는 형태로 운영할 수도 있습니다.
2) Item Filtering
앞서 언급했듯이 특정 비인기 카테고리에 가중치를 차등한다와 같은 비교적 Soft한 필터링도 존재하겠지만, 이미 고객이 가입한 상품이거나, 또한 가입 자체가 불가능한 상품을 추천 대상에서 제외하는 것과 같은 Hard한 필터링의 단계도 필요합니다.
3) 고객 피로도(Fatigue)관리
아무리 고객이 선호하는 상품이라도 같은 컨텐츠의 배너를 너무 자주 노출하면(광고성 배너) 피로도만 쌓여서 오히려 개인화가 역효과가 나게 됩니다. 이렇게 이미 가입하거나 자주 봤지만 가입할 생각이 없는 했던 컨텐츠나, 너무 자주 노출되었던 컨텐츠를 추천에서 제외시킴으로써 새로운 맞춤 컨텐츠를 보게 되는 재미도 제공해줄 수 있습니다.
최종적으로 후처리 step에서 필터링 작업 완료 후 재정렬 과정(추천상품이 비어있을 경우 채워주는 작업)을 한 뒤 고객에게 노출되도록 채널(App)에 정보를 전달하게 됩니다.
Explicit Feedback 정보를 활용한 추가 보완
추천을 위해 고객의 행동 데이터를 볼 때, 두가지의 맥락으로 고객 행동 데이터를 바라봐야 합니다.
Implicit Feedback (암묵적 피드백) : Click , 체류시간, 계약 이력 선호 추정
Explicit Feedback (명시적 피드백) : 고객이 직접 입력한 명시적 선호 정보
지금까지는 오롯이 앱내 고객이 남긴 행동 정보로 Implicit Feedback데이터만 활용을 하여 분석 했습니다. 추후 올 하반기부터는 Explicit Feedback정보(직접 입력한 선호 정보: Zero party data)를 고객으로부터 수집하여 추천의 정확도를 높이려고 합니다.

자동화된 추천 결과 서빙 Process
당행은 올해부터 클라우드 기반의 AWS 도입을 통해 보다 효율적인 환경에서 모델 학습 부터 서빙, 모니터링까지 파이프라인을 구축할 수 있었습니다.
AWS도입 이전엔 MLOps 작업환경을 위해 개인화 추천시스템의 단계별 관리포인트이 많았는데, 대부분의 주요 작업을 통합할 수 있었습니다. 아래 그림은 간략하게 ML Pipeline을 도식화 한 내용입니다.

최종적으로 앱에서 컨텐츠가 노출되기 위해선 계산된 카테고리별 확률순서별로 노출 배너가 결정이 됩니다. 본 추천시스템은 상품추천이 아닌 컨텐츠 추천이다보니 각 카테고리별 컨텐츠배너가 매핑이 되어야 합니다.
Bigdata분석계에선 각각의 상품 및 서비스 영역별 후보 컨텐츠가 준비되어 있고, 앱노출 채널계의 최근 7일간 고객의 행동에 따른 컨텐츠들이 매핑이 되어 노출 됩니다.

컨텐츠는 각 Business담당자들에 의해 제작되고 있고, 컨텐츠별 효율(CTR) 최적화 작업을 통해 노출 효율을 높이고 있습니다. 고객의 추천배너를 보고 행동한 결과에 따라 다음 컨텐츠를 보여줄 것인지, 아니면 가입이 이루어 질때 까지 보여줄 것인지, 아예 다른 카테고리를 보여줄것인지를 결정 하게 됩니다.
이를 통해 고객이 해당 카테고리에 선호도가 높더라도 똑같은 내용으로 넛지하는 것이 아닌 고객이 컨텐츠를 보고난 행동을 기반으로 배너내용을 Refresh하고 있습니다.
개인화 Performance 측정
개인화의 효과 검증을 위해 여러 측면에서 검증을 해봤습니다. 검증을 위한 index는 CTR(Click Through Rate: 노출건수 대비 클릭건수) 과 고객이 경험한 카테고리 수 두가지 지표를 메인으로 하여 Test해봤습니다.
실험군(Test Group) : MLOps로 도출된 추천배너 노출(개인별로 다른 배너)
대조군(Control Group) : 비즈니스 담당자가 직접 Targeting하여 적용한 배너
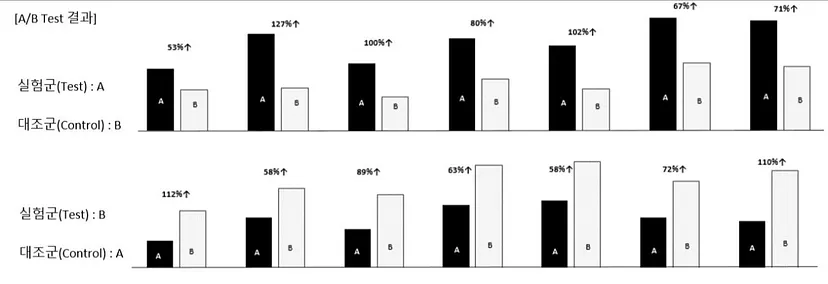
1, 2차에 걸쳐서 A집단을 기준으로 한주는 실험군으로 다음 한주는 대조군으로 교체하여 검증해봤습니다.(1차는 고객번호가 홀수인 고객을 실험군으로, 2차는 고객번호가 짝수인 고객을 실험군으로 설정하여 테스트)위의 그림은 실험군과 대조군 간의 CTR지표 입니다. 실험군이 대조군대비 50~100% 높은것으로 볼 수 있습니다.
또한 인당 경험하게 되는 카테고리 경험 갯수는 대조군 대비 13% 높았습니다. CTR도 당연히 중요한 수치이지만, 고객이 앱에서 경험하는 상품 및 서비스 카테고리 갯수는 고객의 LTV(Life Time Value)와 직결되어 고객의 유지율에 직접적인 영향을 주는 주요 변인 입니다. (앱경험 카테고리 경험갯수와 고객의 유지율(retention rate)는 강한 상관 관계를 보임)
지금 까지 개인화 컨텐츠 추천이라는 주제하에 A to Z를 다루어 보았습니다. 실제 운영을 하다보면 알고리즘이나 자동화된 시스템은 물론이고, 실질적인 효과를 높이기 위해선 컨텐츠를 생산해내는 UX Writing과 채널에서 노출하는 방식, 배너 Refresh 주기 등이 아주 중요 요소로 실적에 영향을 미쳤습니다.
* 개인화추천 연구는 Data-biz팀 이상현, 조용걸님과 함께 끊임없는 문제제기와 그에 따른 가설을 세워 만들어 가고 있습니다.
긴글 읽어주셔서 감사합니다.
케이뱅크와 함께 하고 싶다면 🚀
'Tech' 카테고리의 다른 글
| 케이뱅크 개인화 프로젝트들은 어떤 구조로 만들어졌을까? (1) | 2023.08.16 |
|---|---|
| 코딩 없이 업무 자동화하기 (0) | 2023.08.10 |
| 코드 한 줄 없는 딥러닝으로 문서에서 지문 찾기! (0) | 2023.08.04 |
| 오픈소스를 활용한 딥러닝 얼굴인식 맛보기 (Feat. DeepFace) (0) | 2023.08.04 |
| 자산관리를 위한 데이터 수집과 탐색 (0) | 2023.08.03 |