
2023. 8. 3.ㆍTech
0. 목차
- 들어가며
- 자산데이터 수집 (주식, 부동산, 거시경제, 로또)
- 데이터 탐색
- 마치며
1. 들어가며
2022년 하반기에 유행한 드라마 중 ‘재벌집 막내아들’ 이라는 드라마가 있습니다. 이 드라마는 현대의 지식과 역사를 아는 상태로 과거 재벌가의 어린 아들로 다시 한번 인생을 살게되는 드라마입니다. 주인공은 드라마에서 자신만 알고있는 미래의 정보들을 동원해 어린나이에 막대한 재산을 얻게 됩니다.
- 과거로 돌아간다면
많은 사람들이 이 드라마를 보며 비슷한 생각을 한번쯤 해봤을 것 같습니다. ’내가 과거로 돌아간다면 무엇을 할까’ 라는 생각입니다. 주변 지인분들께 물어보았을때, 대부분 현대의 지식을 알고 있는 채로 과거로 돌아간다면 대부분 자신이 알고있는 정보들을 동원해 이렇게 혹은 저렇게 막대한 부를 얻을 것이라는 얘기를 했습니다.
나만 알고 있는 알짜 정보가 있다면 많은 사람들이 돈 혹은 재화와 연결되는 생각을 하곤 합니다. 정보의 비대칭이 확실한 상황에서 이러한 정보들을 이용한다면 내가 얻을 수 있는 이득과 재화가 크게 늘어날 것입니다.
- 현실적으로 가능한 영역
사실 드라마처럼 현대의 지식을 알고 있는채로 과거로 간다는것은 현실적으로 불가능한 일입니다. 하지만 지금의 정보들을 조합해서 자산의 미래를 예측하는 일은 과거로 가는 것보다는 조금 더 실현가능해보입니다. 다만 미래를 예측하기 위해서는 근거로 사용할 수 있는 데이터가 필요합니다. 이번 글에서는 자산시장에서 사용할 수 있는 데이터의 종류와 수집방식에 대해 알아보고 간단한 탐색적 분석을 수행해 보겠습니다.
예상독자는 데이터 수집 방식과 전처리 방식에 대해서 궁금한 분, 자산시장의 데이터를 획득한 뒤 분석을 원하시는 분들이 될것 같습니다.
- 데이터 수집방식과 전처리 방식에 대해서 궁금하신 분
- 데이터를 통한 문제상황 확인과 가정 수립에 대해서 궁금 하신 분
- 다양한 금융데이터의 종류와 활용방안에 대해 궁금하신 분
2. 데이터 수집
2.1 주식 데이터
증권과 관련된 주식 데이터를 가져오기 위해서는 다양한 방식이 존재합니다. 정석적인 루트는 개별 증권사에서 제공하는 api를 통해 허용된 루트로 데이터를 가져오는 방식입니다. 안정적으로 기술 지원을 받으며 데이터를 가져올 수 있습니다. 또한 수집 뿐 아니라 필요시에 API 를 이용해 증권사 서비스에서의 기능을 모두 자동화 할수 있다는 장점이 있습니다.
국내에서 가장 많이 사용되고 예시 자료가 풍부한 것은 키움의 api입니다. 하지만 해당 방식에는 허들이 존재합니다. 우선 국내의 증권사에서 제공하는 API는 윈도우 기반 운영체제에서만 동작하게 되어있고, 일반적인 64bit가 아닌 32bit 환경에서만 동작이 됩니다. 또한 api를 제대로 사용하기 위해서는 특유의 사용방식에 대해서 학습할 필요가 있습니다. 안정적인것은 장점이지만, 특정한 시스템 환경에 종속되어서 사용가능하다는 점은 빠르게 poc를 진행하거나 데이터를 확인해보고 싶은 입장에서는 분명한 장애물입니다.
- 키움 api 사용 준비를 위한 step
- 윈도우 운영체제 준비
- python 32-bit 환경 준비(가상환경)
- (비대면) 키움계좌 계설
- 키움 홈페이지에서 open api 사용신청
- 모의투자신청
- open api+ 모듈 다운로드
- KOA studio 다운로드
- koa api 를 통한 계좌 로그인 및 데이터 처리 수행
# 키움 api 를 통한 로그인 수행방식 (API체계에 대한 학습 필요)
import sys
from PyQt5.QtWidgets import *
from PyQt5.QAxContainer import *
class MyWindow(QMainWindow):
def __init__(self):
super().__init__()
self.ocx = QAxWidget("KHOPENAPI.KHOpenAPICtrl.1")
self.ocx.dynamicCall("CommConnect()")
self.ocx.OnEventConnect.connect(self.OnEventConnect)
def OnEventConnect(self, err_code):
print(err_code)
app = QApplication(sys.argv)
window = MyWindow()
window.show()
app.exec_()절차에 따라 로그인을 한 뒤 api에서 제공하는 기능들을 사용해 데이터를 수집해야 합니다. 이 방식을 능숙하게 습득하게 된다면 데이터 수집 뿐 아니라 증권사에서 수행할수있는 모든 행동을 해당 api를 통해 프로그래밍 할수 있습니다.
하지만 우선 데이터 수집만 목표로 하기 위해 조금 쉬운방식으로 먼저 데이터를 확인해보겠습니다. 공개되어 있는 라이브러리 중에 pykrx라는 파이썬 라이브러리가 존재합니다. 해당 라이브러리는 웹 크롤링 방식을 사용합니다. naver와 krx (한국거래소)의 웹사이트를 통해서 크롤링을 해오는 라이브러리 입니다. 웹페이지에서 정보를 수집해오기 때문에 특정 운영시스템에 종속되지 않고, 가볍게 사용할 수 있습니다.이 방식은 데이터를 수집하는 기능만 지원을 하고, 데이터의 정합성이 보장되지 않는다는 점과 open api 와 같은 직접적인 데이터 제공사의 기술적 지원이 뒤떨어진다는 단점이 존재합니다. 하지만 poc 수행을 위해서 빠르고 손쉽게 사용할 수 있다는 장점이 있습니다.
- pykrx 를 통한 데이터수집
!pip install pykrx
from pykrx import stock
from pykrx import bond
KOSPI_tickers = stock.get_market_ticker_list("20190225")
KOSDAQ_tickers = stock.get_market_ticker_list("20190225", market="KOSDAQ")
df = stock.get_market_ohlcv("20220720", "20220810", "005930") # 시작날짜, 종료날짜, tickers
print(df.head(3))
'''
시가 고가 저가 종가 거래량 거래대금 등락률
날짜
2022-07-20 61800 62100 60500 60500 16782238 1025939109200 -0.66
2022-07-21 61100 61900 60700 61800 12291374 754854999650 2.15
2022-07-22 61800 62200 61200 61300 10261310 631872940300 -0.81
'''주식데이터를 수집할때 ohlcv 라는 용어를 많이 사용합니다. 해당 컬럼은 대부분의 증권사 api 나 크롤링 방식 혹은 데이터를 다루는 데이서에서 많이 사용하는 컬럼입니다.
- o : open ~ 오픈가
- h : high ~ 고가
- l : lower ~ 저가
- c : close ~ 종가
- v : volume ~ 거래량
2.2 부동산 데이터 (아파트)
한국의 부동산 데이터 정보를 얻기 위해서는 공공데이터 포털에서 open api 를 통한 방식이 가능합니다. 국토교통부는 2006년 1월1일 부터 시행된 ‘부동산실거래가 신고제도’에 의해 모든 부동산의 실거래가격을 신고받고 있습니다. 거래 신고는 거래 계약의 체결일부터 30일 이내에 실제 거래가격으로 시·군·구청에 이루어져야 합니다. 중개업자가 거래 계약서를 작성·교부한 경우에는 반드시 중개업자가 신고를 하여야 합니다
다행히 공공데이터포털을 통한 데이터 접근은 쉬운편이고 데이터를 접근한다면 전국에서 실제 거래가 이뤄졌던 데이터를 모두 가져올 수 있습니다. 아쉬운 점은, 현재는 30일 동안의 신고 유예기간이 정해져있어 거래계약이 이루어지는 모든 시점에서의 거래가 아닌 30일 이전에 거래 계약이 완료된 데이터만 확정적으로 수집되고 있다는 것입니다.
- 공공데이터 포털 api 사용 방식
- 공공데이터 포털 계정생성 (https://www.data.go.kr/)
- API 활용신청 (데이터 명 : 국토교통부_아파트 매매 실거래 상세 자료)
- 데이터 호출
import requests
# 법정동코드
LAWD_CD = '11110' # 예시 : 서울특별시 종로구
# 호출 희망 연,월
DEAL_YMD = '200601'
url = 'http://openapi.molit.go.kr/OpenAPI_ToolInstallPackage/service/rest/RTMSOBJSvc/getRTMSDataSvcAptTradeDev'
params ={'serviceKey' : API_KEY, 'pageNo' : '1', 'numOfRows' : '10000', 'LAWD_CD' : LAWD_CD, 'DEAL_YMD' : DEAL_YMD }
response = requests.get(url, params=params)
result = response.text공공데이터 포털에 로그인 후 api 신청을 하면 key 가 발급이 됩니다. api 등록 절차에 필요한 1~2시간의 대기시간 후 발급된 키를 통해 데이터를 수집 할 수 있습니다. 데이터는 xml 형태이며 데이터 호출 후 별도의 파싱 과정을 통해 데이터를 사용하실수 있습니다.
api 활용신청을 한 1개 개발계정마다 1일 1000회만 호출이 가능하기에 획득할 수 있는 데이터 양은 한정적입니다. 1개 지역구(법정동)의 전체 데이터를 획득하기 위해서는 약 2006년 1월부터 2022년 12월 기준 약 204번의 api 호출이 필요합니다. 따라서 1개의 개발계정당 하루에 데이터를 획득할수 있는 법정동 전체 데이터는 호출제한에 의해 4개 지역구(법정동)입니다. 운영계정은 api 호출1 제한이 몇만건으로 크게 늘어나게 되는데요 신청을 위해서는 수집된 데이터를 통한 app 또는 서비스페이지에 대한 근거자료 제출이 필요합니다.
지역구 코드는 API 에서 ‘LAWD_CD’ 라는 코드값을 사용합니다. 이 코드값은 정부에서 사용하는 행정표준코드 관리 시스템의 법정동코드라는 값을 사용합니다. 이 코드값에서 앞의 5개자리 숫자를 추출한 값을 지역구 코드로 사용하고 있습니다. 전국의 모든 지역코드를 가져오려면 현재기준 총 261개의 지역코드를 확인할 필요가 있습니다.
- 지역구 코드 key 값 (LAWD_CD)
- www.code.go.kr
- 자료명 : 법정동코드
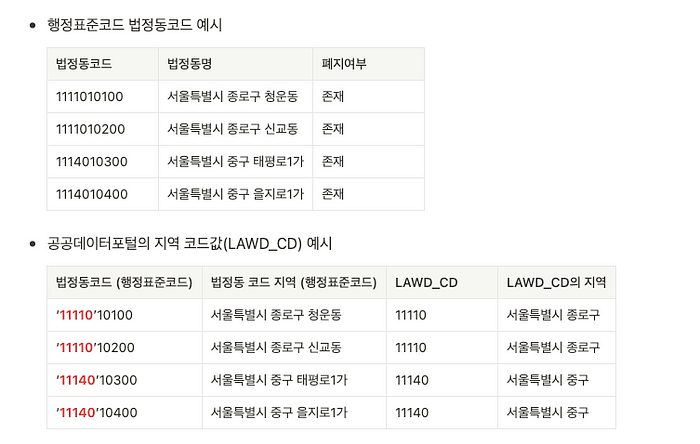
데이터의 출처에서 데이터를 가져온 뒤에 법정동코드에서 앞 5자리의 숫자를 코드값으로 사용해 이를 대표하는 법정동 코드 지역을 추출해 사용해야 합니다.
2.3 거시경제 지표 데이터
주식이나 부동산은 자체적으로 해당 자산의 특정한 패턴을 따라 주기적으로 움직이는 데이터는 아닙니다. 다양한 외부변수들이 시장상황에 개입을 하며 자산의 가격이 급변할 수 있습니다. 자산의 외부변수로 사용할 수 있는 가장 대표적인 변수는 거시경제 데이터입니다. 금리, 실업률, 물가 등 경제의 전반적인 상황을 확인할 수 있는 변수로 자산의 데이터와 함께 분석을 할 수 있습니다. 이를 통해 각 자산의 개별현황만 아니라 각 주체들간 상호작용하는 현상을 분석하여, 미래를 예측하는데에 다각도의 변수로 활용할 수 있습니다.
국내의 이런 종류의 데이터를 획득할 수 있는 방안으로 조금전 확인했던 부동산 데이터와 같이 공공데이터 포털에서 관련된 데이터를 획득할 수 있습니다. 하지만 하나의 서비스나 api 로 통합되어 있지 않고 데이터 형태도 제각기 다르기 때문에 개별로 전처리 프로세스를 따로 확인해야하며 그 종류가 아직까지 다양하지 않다는 단점이 있습니다.
손쉽게 거시경제에 대한 데이터를 확인하기 위해 FRED 를 이용하는 방법이 있습니다. FRED는 미국 세인트루이스 연방준비은행에서 관리하는 데이터입니다. 해당 시스템을 통해 국가 경제, 공공 및 민간출처의 수십만개의 경제 시계열 데이터를 조회하고 수집할 수 있습니다. 사실상 미국의 거시경제는 전세계의 경제에 영향을 미치고 있기 때문에 해당 데이터를 사용해 분석을 시도해보는것은 유의미하다 판단됩니다.
실제로 글을 쓰는 시점인 2023년 1월 초 작년(2022년)의 12월 미국의 소비자물가지수(CPI)의 발표를 앞두고 시장의 예측과 다르게 인플레이션이 완화될것이라는 가능성이 생겼고 이에 따라 나스닥이 거래일 연속 상승을 했습니다. 이유는 미연준은 현재까지 물가를 이유로 금리를 높여왔는데 소비자물가지수가 시장의 생각보다 낮게 나타남에 따라 미연준의 금리 인상속도가 줄어들수 있다는 기대심리가 퍼졌기 때문입니다. 미 증시시장의 반등세와 미연준의 금리 인상속도가 줄어들수 있다는 기대심리로 인하여 국내 증시시장도 반등을 하기도 했습니다. 만약 거시경제 데이터가 자산데이터에 미치는 영향을 적절하게 분석 할 수 있다면 더욱 많은 이득을 얻을 수 있을 것입니다.
- FRED 데이터 사용
- 포털 계정생성 (https://fred.stlouisfed.org/)
- api 키 발급 (https://fredaccount.stlouisfed.org/apikeys)
!pip install fredapi
from fredapi import Fred
fred = Fred(api_key = API_KEY)
data = fred.get_series('CPIAUCSL') # 소비자물가지수
위에서 언급한 CPI (소비자물가)지수역시 해당 API 를 통해서 획득할 수 있습니다. 정말 다양한 지표와 데이터를 Fred 포털을 통해서 획득 할 수 있습니다. 대표적으로 아래 데이터들을 손쉽게 확인할 수 있습니다.
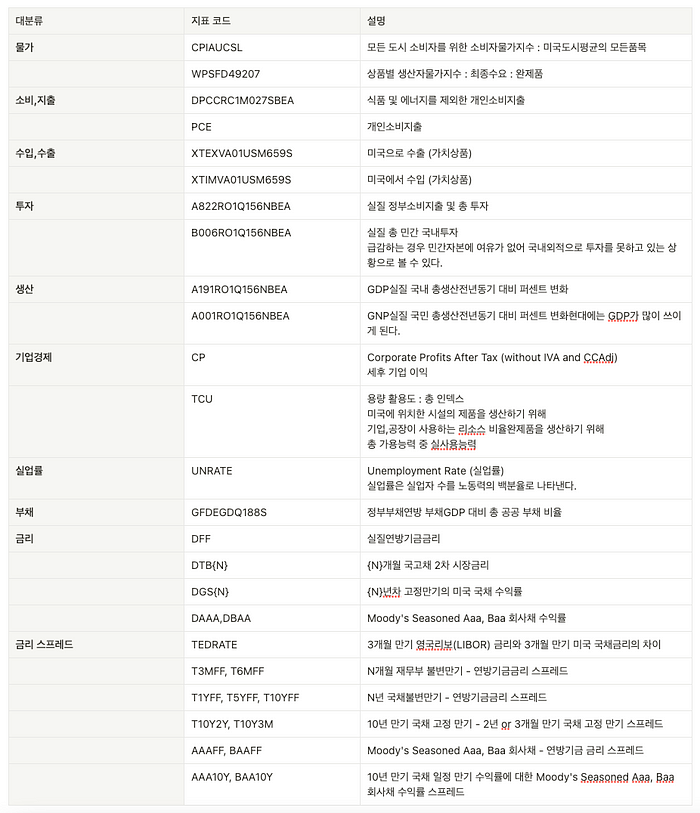
2.4 로또 데이터
이 부분은 재미 위주의 데이터 수집입니다. 앞의 주식이나 부동산이 개인이 노력을 통해 돈을 벌 수 있는 확률을 올릴 수 있는 자산관리의 영역이라고 생각합니다. 하지만 로또의 경우는 사실 자산관리와 다른 영역입니다. 무작위 숫자가 매 회차마다 추출되는 것이기 때문에 사실상 예측은 불가능합니다.
하지만 이는 실제 시행이 무작위 하다는 가정에서의 어려움입니다. 만약에 시행이 무작위 하지 않고 특정패턴을 가지고 있다는 것이 증명된다면 미래에 나올 패턴을 예측하는 것도 가능할 것입니다. 물론 시행은 무작위 하겠지만 분석을 한다면 특정 패턴을 가지고 있는지 확인하는 것이 우선일 것입니다.
아래의 방식은 나눔로또 사이트에서 공식적으로 공개 되어있는 루트는 아닙니다. 해당 URL뒤에 회차를 입력하면 로또당첨결과가 json 형태로 제공됩니다.
import pandas as pd
from urllib.request import urlopen
import json
def lotto(number):
url="http://www.dhlottery.co.kr/common.do?method=getLottoNumber&drwNo="+str(number)
result_data = urlopen(url)
result = result_data.read()
json_data = json.loads(result)
dict_data = pd.DataFrame.from_dict(json_data,orient='index')
pd_data = dict_data.transpose()
return pd_data데이터를 확인해보면 아래와 같은 정보들이 수집된것을 알 수 있습니다.
- totSellamnt: 총상금액
- returnValue: 실행결과
- drwNoDate: 추첨 일자
- firstWinamnt: 1등 당첨금
- firstPrzwnerCo: 1등 당첨 인원
- bnusNo:보너스 번호
- drwNo: 회차
- drwtNo1~6: 당첨번호 숫자
3. 데이터 탐색
다양한 형태의 자산과 관련된 데이터들을 수집을 해보았습니다. 수집한 데이터들을 가지고 예측이나 추천 알고리즘을 통해 더 좋은 전략을 세울수 있을 것입니다. 또는 미래 리스크를 탐지하여 회피 할 수 있을것입니다.그전에 우선 수집한 데이터에서 나타나는 특징은 어떻게 이루어지고 있는지 확인을 해보기 위해 탐색을 해보았습니다.
3.1 주식
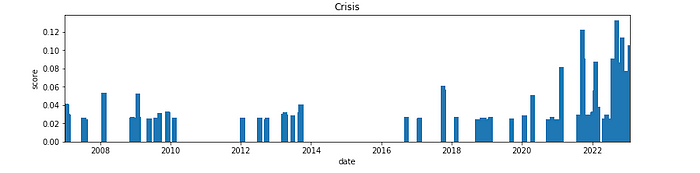
아래 데이터는 코스피의 업종의 지수 데이터입니다.과거부터 상승과 하락을 반복하며 현재까지 크게 상승해 온 것을 알 수 있습니다. 데이터의 중간중간에는 크게 하락하는 구간이 있습니다. 이러한 구간들을 피할 수 있다면 리스크를 회피함으로써 기존 시장보다 더 많은 이득을 얻을 수 있는 기회가 될 것입니다.
우선 크게 하락하는 구간에 대해 실제 일정 수치 이상 하락하는 구간을 추출해 리스크가 존재하는 위기구간 판별을 수행해보겠습니다.방식은 각 단변량 시계열에 대해 스무딩방식을 적용한 뒤 예측값을 특정 기준치(변동량의 배수) 만큼 벗어나는 곳을 위기구간이라고 가정하였습니다. 두번째 그래프의 빨간 점은 특정 기준치를 크게 벗어난 지점입니다.
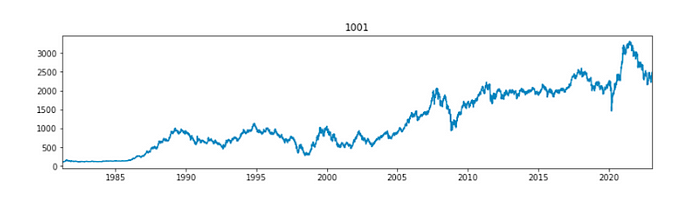

위와 같은 과정을 수집한 국내의 총 98개 업종별 지수데이터에 적용하였습니다. 기준치를 크게 벗어날 수록 가중치를 더하여 전체 이상 급변점에 대해서 확인을 했고 그 결과는 아래와 같습니다.
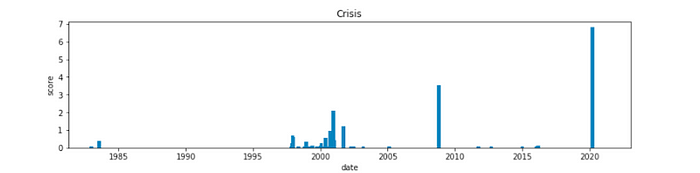
크게 3개 구간이 확실하게 확인이 되고 있습니다. 2000년대 전후 시점과 2008년 그리고 2020년 초반이 주식의 업종데이터에서 급변한 지점으로 나타났습니다. 실제 해당 시점에서는 아래와 같은 경제위기를 겪은 사실이 있습니다.
- 1998년 :한국 IMF에 의한 경제 위기
- 2000년 :닷컴버블 붕괴로 인한 경제 위기
- 2008년 :서브프라임 모기지론에 의한 경제 위기
- 2020년 : 코로나 경제 위기
자산이 급변한 시점에 대해서 실질적인 수치로 확인 할 수 있게 되었습니다. 이후에 할 수 있는 분석 방법은 직접 단변량 데이터에 대해 상승과 하락을 예측할 수 있을 것입니다. 또는 급변한 시점 전후로 다른 변수들에 끼친 영향을 분석하여 변수들과 관계를 통해 이후 시점의 움직임에 대해 예측할 수 있을 것 입니다.
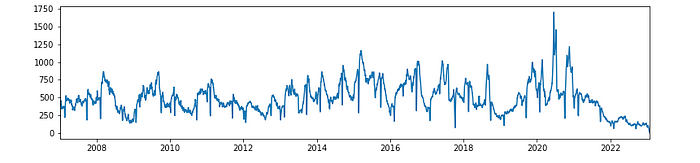
3.2 부동산
주식과 유사한 방식을 통해 부동산 시장의 급변지점을 확인해보겠습니다. 확인가능한 2006년 이후로 급변지점에 대한 수치는 비슷한 수치를 보였습니다. 2022년 부터는 그 수치가 상대적으로 크게 증가한 것을 볼 수 있습니다. 2022년부터 시작되어 2023년 초 현재까지 부동산 시장의 상승세가 둔화되고 하락하고 있는 지역이 나타나고 있어 이 지점이 급변지점으로 확인이 되고 있습니다.
아래 데이터는 거래량 데이터입니다. 데이터를 그대로 확인하면 변동성이 워낙 크기 때문에 smooting 전처리를 통해 추세만을 확인해보았습니다.
부동산에서 중요한 것은 거래량 지표라고 합니다. 최근 뉴스를 보게 되면 거래량 절벽으로 인해 부동산 하락에 대한 우려가 커지고 있는 상황입니다. 실제 데이터의 결과도 2022년 이후 과거 데이터에 비해서 거래량의 하락세가 두드러지게 보이고 있습니다.
3.3 거시경제 데이터
거시 경제 데이터에 대한 분석은 그 자체로 의미가 있지만, 실제 자산시장에 대해서 어떻게 영향을 끼치고 있는가에 대한 분석을 한다면 자산시장 예측과 리스크 회피에 큰 도움이 될 수 있습니다.
주식시장에서 분석한 자산의 급변지점은 3개 파트로 각각 2000년 전후시점과 2008년, 2020년으로 나눌 수 있습니다. 만약 특정 거시경제 데이터에서 각 자산 급변지점 이전에 특정 신호를 확인할 수 있다면 해당 데이터를 통해 급변지점이 나타날 것을 예측하거나 대비를 할 수 있을 것입니다.
아래 세개의 그래프는 각각 2000년대 초반과 2008년, 2020년 급변지점으로 나타났던 구간을 특정 시점만 추출해온 것입니다. 급변한 지점을 탐색한 것과 같은 방식으로 위에 거시경제 데이터 예시테이블에서 언급한 데이터에 대해 적용을 해보았습니다. 이후 주식업종의 데이터와 거시경제 데이터의 급변점 데이터를 동일 시계열 선상에 두고 가중치 막대 그래프로 표시를 해보았습니다. 빨간색 막대는 거시경제 데이터의 급변지점을 의미하고, 파란색 막대는 주식시장의 급변지점을 의미합니다.


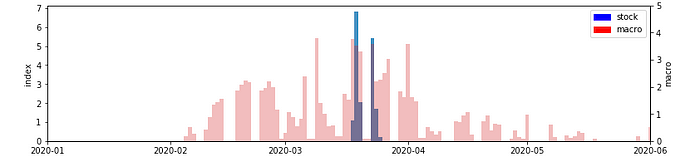
시각화 결과 주식 업종의 각 급변지점보다 먼저 크게 급변한 거시경제 지표가 있는 것으로 확인되고 있습니다. 이 현상은 2008년과 2020년 더욱 눈에 띄게 나타납니다. 만약 주식 업종이 급변하기전 나타난 거시경제 지표의 신호를 포착해 급변지점에서 기회를 노리거나 리스크를 회피했다면분명 많은 자산을 획득 할 수 있는 기회가 될 것입니다.
3.4 로또
로또는 1부터 45까지의 숫자 중 6개의 번호와 1개의 보너스 번호를 순차적으로 뽑는 게임입니다. 이 게임은 뽑힌 번호를 제외하고 그 나머지 번호에서 다시 하나의 번호를 뽑게 됩니다. 이를 비복원추출이라고 합니다.
데이터가 뽑히는 기준은 비복원추출이며 한개의 번호가 뽑힌 뒤 다른 번호가 추출될 확률은 유동적으로 변합니다. 하지만 결국 최종적으로 각 번호가 뽑힐 확률은 모두 동일합니다. 이 동일한 확률이 복권이 랜덤하다는 기본 가정입니다. 그렇다면 이러한 기본가정이 실제 만족하는지 데이터를 통해 확인해보겠습니다. 현재까지 시행회차인 1052회에 매회차에 뽑는 숫자의 갯수 7을 곱한 뒤 이를 전체 번호의 갯수 45로 나누면 163.6이라는 숫자가 나오게 됩니다. 이는 각 번호가 이제까지의 시행에서 뽑혔어야 할 기대값입니다. 1부터 45까지의 전체 숫자가 총 1052번의 시행에서 추출된 횟수를 모두 세어본다면 아래와 같은 막대그래프를 확인할 수 있습니다. 이 그래프에서 각 숫자가 뽑혔을 기대값이 163.6보다 낮은 숫자는 파란색으로 표시를 하고 이 시행보다 높은 숫자는 빨간색으로 표시를 했습니다.
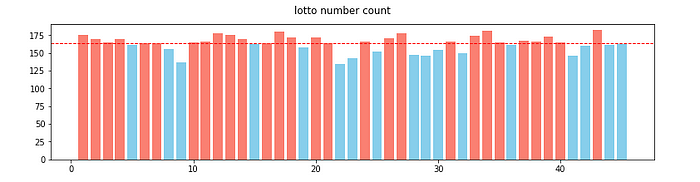
결과적으로 아래 17개 숫자는 기대값보다 덜 뽑힌것을 알 수 있습니다. 그중 22라는 숫자는 총 135번 뽑힘으로 기대값의 82%로 기대수치에 비해 현저하게 적게 뽑히고 있습니다.
- 기대값보다 덜 뽑힌 번호 : 5,8,9,15,19,22,23,25,28,29,30,32,36,41,42,44,45
가능성은 2가지가 있습니다.
(1) 첫번째는 대수의 법칙에 의한 것입니다. 현재까지 뽑히지 않았던 숫자들이 기대값에 수렴하도록 앞으로의 미래시행에서 더 많이 뽑히게 될것이라는 통계적 가정을 할 수 있을것 같습니다.
(2) 두번째는 현실적인 가정입니다. 현재까지 뽑히지 않았던 숫자는 다른 숫자에 비해 상대적으로 공이 무겁거나 한것과 같은 현실적인 오류로 인해 덜 뽑힐 수 있다는 가정입니다.
만약 첫번째 가정이 맞다면 지금까지 덜뽑혔던 숫자로 조합해 복권을 구입해야할것이고, 두번째 가정이 맞다면 지금까지 많이 뽑혔던 숫자를 조합해 복권을 구입해야 할 것 입니다. 물론 단순한 가정이기에 어떤 가정이 맞을지는 앞으로의 당첨 조합을 확인해 봐야 할 것 같습니다.
4. 마치며
지금까지 자산데이터의 종류와 수집방식 그리고 탐색을 수행해보았습니다. 여기에서 소개한 데이터는 자산데이터 중 일부일 뿐입니다. 수많은 자산과 관련된 영역과 관련 데이터들이 존재하고 있습니다.
자산 데이터들을 통해 만약 남들은 알지 못하는 새로운 통찰을 발견하게 된다면해당영역에서의 작은 통찰은 현실적 보상을 얻을 수 있는 기회가 될 것입니다. 미래를 예측하거나, 특정 자산을 추천할 수도 있을 것이고 혹은 시장 리스크가 분명한 상황을 회피하며 위기관리 측면의 자산관리 역시 수행할 수 있을 것입니다.
이후에는 수집된 데이터들과 해당 포스팅에서 소개되지 않은 수많은 자산 관련 데이터들을 통해 자산관리 측면에서의 통찰을 얻기위해 분석과 모델링 작업을 수행해보고자 합니다.
케이뱅크와 함께 하고 싶다면 🚀
'Tech' 카테고리의 다른 글
| 케이뱅크 개인화 프로젝트들은 어떤 구조로 만들어졌을까? (1) | 2023.08.16 |
|---|---|
| 코딩 없이 업무 자동화하기 (0) | 2023.08.10 |
| ML(Machine Learning)기반 개인화 Content 추천시스템 개발기 (2) | 2023.08.09 |
| 코드 한 줄 없는 딥러닝으로 문서에서 지문 찾기! (0) | 2023.08.04 |
| 오픈소스를 활용한 딥러닝 얼굴인식 맛보기 (Feat. DeepFace) (0) | 2023.08.04 |