
2023. 11. 29.ㆍTech
안녕하세요. Data Biz팀 김진식이라고 합니다. 저희 팀은 데이터를 통해 고객 접점 비즈니스 가치를 만들어가는 다양한 업무를 수행하고 있습니다. 개인화나 다양한 AI 기술의 활용, 제휴 데이터 수집/가공, 데이터 기반 캠페인 자동화/타겟팅 등이 대표적인 업무입니다.
이 글은 아래와 같이 이루어져 있습니다.
ㅇ1부
. 개괄
. 인공 신경망, 연결주의 소개, 딥러닝이 나오기 전까지
. 이미지 인식의 고성능 모델 등장, CNN 그리고 AlphaGo
. Transformer의 등장
. Transformer 학습하기
. GPT가 달려온 길
. ChatGPT 미래는 어떻게 전개될까요?
. LLM의 역사 마무리
ㅇ2부
. 금융 적용 가능 분야 탐색
. 생성형AI의 어느 단계까지 내재화 대응할까요?
. 오픈소스 모델을 사용하는 것은 어떨까요?
. 망분리, 개인정보보호, on-prem/cloud의 복합문제
. 일단 응용분야를 정했다면 어떻게 해야 할까요?
. LLM은 어떤 모델들에 주목해야 할까요?
. 기타
본 글의 예상 독자는 다음과 같습니다.
. 대형언어모델(Large Language Model)에 대해 관심이 있거나 응용을 고민하시는 분
. 최근의 딥러닝 AI 트렌드에 대해 알고 싶은 분
. 금융에서 대형언어모델이 어떻게 사용될 수 있고, 어떤 방향을 잡아야 할지 고민하시는 분
개괄
2022년 12월 OpenAI에서 ChatGPT 서비스를 출시한 이래로, 대형언어모델(LLM)은 빅테크들의 전략과 IT산업의 방향을 바꾸어 나가면서 최고의 관심을 받고 있습니다. 초기 OpenAI의 GPT-3에서, GPT-4를 거쳐 GPT-4-turbo, 그리고 이미지 생성(DALL-E 3)이나 다양한 플러그인 결합, 각기 채팅 AI에 개성을 부여하는 GTPs의 스토어화까지 숨 가쁘게 업그레이드되고 있으며, 많은 사람들이 정신없이 그리고 어렴풋이 이 변화를 지켜보게 되었습니다.
누군가는 지금 이 시점을 과거 스마트폰/아이폰이 처음 나오던 시기를 빗대어 또 다른 빅테크들과 새로운 역사적 효율성 혁신이 탄생할 빅뱅의 초기라고 합니다. 그렇게 인류의 생산성을 크게 진보시킬 새로운 산업이 열리고 있을지 모릅니다. 그러면 AI 관련 비즈니스나 기술 담당자들은 이 LLM을 어떻게 보아야 할까요? 여러 가지 용어를 이해하고 지금의 상태를 되돌아보고, 앞으로를 그나마 최대한 중장기 관점에서 전망해 보기 위해 빠르게 훑어보겠습니다. 일단 ChatGPT의 기반이 되는 신경망/딥러닝부터 시작해 보겠습니다.

인공 신경망, 연결주의 소개, 딥러닝이 나오기 전까지
LLM(Large Language Model), 즉 ChatGPT로 대표되는 현재의 이 생성형 AI(Generative AI)들의 본질에 대해 OpenAI의 수석 과학자 Ilya Sutskever는 “digital brain”이라고 표현합니다*. Sutskever는 지금 당신을 놀라게 하는 모든 AI 서비스가 모두 digital brain에서 유래하고 있다고 말합니다. 그러면 digital brain이란 무엇일까요? 이는 생물학적 뇌를 흉내 낸 복잡한 인공 신경망을 만들어 학습시킨 소위 딥러닝(Deep Learning) 기반의 대규모 신경망으로 된 AI를 의미합니다.
*TED Talk : Ilya Sutskever https://www.ted.com/talks/ilya_sutskever_the_exciting_perilous_journey_toward_agi
2차 세계대전 전후 디지털 컴퓨터가 고안된 초기부터 AI는 오랜 인간의 관심사였습니다. 전산학 교과서에 나오던 폰 노이만(John Von Neumann)이나 앨런 튜링(Alan Turing)이 활동하던 1930년대부터, 최초의 디지털 컴퓨터가 만들어지던 시절에도 결국에는 이것이 사람과 똑같은 지능을 가질 수 있다는 AI에 대한 여러 가지 주장이 있었습니다. 그리고 앨런 튜링은 대화를 하면서 상대방이 사람과 구별을 할 수 없다면 그것이 컴퓨터가 지능을 갖고 있다고 판별할 수 있다는 Turing Test를 주장하기도 했습니다.
이 초기 시기부터도, AI를 구현하는 방식에는 두 가지 흐름이 있었는데, 바로 기호주의(Symbolism)와 연결주의(Connectionism)입니다. 기호주의란 현재의 소프트웨어 엔지니어에게 가장 익숙한 방식이며, if/then/for/while 등의 여러 가지 기호로 적절히 논리적인 프로그램을 구성하여 기계가 자동으로 무언가를 처리하게 하고, 이것이 발전하면서 기계가 지능을 갖게 한다는 생각입니다. Rule기반이라고 표현되기도 하며, 현대의 개발자라면 익숙한 그런 방식이라고 간단히 이야기해 볼 수 있습니다.
반면에 digital brain이란 연결주의에 기초합니다. 즉, 생물학적인 뇌처럼 동일한 기능을 하는 단순한 인공신경세포가 대규모로 연결되고, 그 각각 연결의 가중치만 학습을 통해 잘 조절하면, 지능을 갖게 할 수 있다는 믿음입니다. 사람의 지능이란 단순히 이해하기에는 매우 복잡한 속성이 있어서, 규칙 코딩만으로 해결할 수 없고, 대규모 인공신경의 작동이 창발성(기존과 완전히 다른 기능을 갑자기 나타내는 현상)을 일으켜 지능을 만들 것이라는 주장으로, 1957년에 퍼셉트론이라는 것이 제안되며 그 첫걸음을 시작했습니다.
2개의 입력값과 가중치, 1개의 출력값을 갖는 가장 기본적인 퍼셉트론 예시 중 하나는 아래와 같이 묘사되는데, 이 가중치 w의 값에 따라 y가 결정되는 간단한 구조입니다. 향후 용어에 대한 이해를 위해 간단히 살펴보도록 하겠습니다.

예를 들자면, x1, x2에 각기 사람의 몸무게와 키를 각각 입력하고, 가중치 w1, w2를 적절히 조절해서 y값에 따라 어떤 무게의 역기를 들 수 있느냐 없느냐로 구분하는 기능을 하도록 만들 수 있습니다. 이를 테면 y가 0보다 크면 역기를 들 수 있고, 0보다 작으면 아니라고 판단하면 됩니다. 이 가중치 값은 과거 측정 데이터를 가지고 적절히 알아내면(학습이라고 표현할 수 있음) 몸무게와 키 수치로 지정된 역기를 들 수 있는지 판별하는 아주 작은 신경세포가 될 수 있습니다.
이 퍼셉트론은 입력이 2개(x)이고 파라미터 개수(w, 가중치 개수)가 2개이고 출력은 1개(y)입니다. 여기서 현재 GPT-3의 175B 파라미터라고 하는 부분이 바로 이 연결/가중치의 개수입니다. 즉 GPT-3는 가중치 2개짜리 퍼셉트론 대비해서 1,750억 개의 연결이 존재하는 신경망인 셈인 것입니다. 하지만 이 단순 퍼셉트론 구조로는 제한된 문제만 풀 수 있습니다. 그러나 연결주의는 이 신경세포 역할을 하는 퍼셉트론을 무수히 더 많은 연결과 다층으로 구성하면 복잡한 문제도 처리할 수 있고, 결국 인간의 생물학적 뇌도 같은 방식이라고 주장합니다. 수많은 가중치를 적당히 학습시킬 전략만 있다면, x에는 우리가 보는 이미지 전체를 넣고, 출력은 어떤 물체인지 맞춘다고 하면, 그것이 바로 인간의 뇌를 닮은 AI가 됩니다. 그리고 그 꿈을 실현하기 위해 1950년대 퍼셉트론에서 출발한 현대의 신경망은 GPT-3처럼 이제 더 복잡해지게 됩니다.
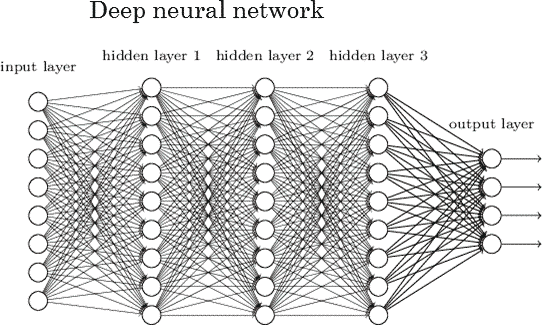
그런데 초기 연구에서 이 신경망의 문제는, 구조가 간단한 경우는 가중치를 구하기가 어렵지 않은데, 연결이 더 많고 복잡해질수록 학습이 매우 어렵다는 점이었습니다. 또한 학습 때마다 그 성능 편차가 심했고, 학습이 최적화되지 않는 방향으로 진행되어 오류가 많다던가, 계산량도 너무 크다는 문제가 있었습니다. 그리고 아이러니하게도 지금에야 알게 되었지만, 작은 크기의 신경망으로는 문제 해결이 어렵다는 것도 있었습니다. 지금도 얼마나 커야 어떤 문제를 해결할 수 있는지를 경험적으로 예측하는 부분이 있습니다. 그래서 이 연결주의에는 한동안 겨울(AI winter)이 찾아옵니다. 처음의 AI에 대한 희망은 사라지고 한동안 개선이 없었고 사람들의 관심에서 일부 멀어져 갔습니다. 우리가 흔히 이야기하는 딥러닝이라는, 거대 신경망에서도 이 가중치 값을 적절히 결정해 주는 몇 가지 학습 전략의 조합이 2000~2010년경 추가로 개발되고, NVIDIA의 게임용으로 만들어진 GPU를 사용해, 이 가중치 계산을 대량 병렬로 처리해 속도가 빨리 지기 전까지, 그리고 학습시킬 충분히 많은 데이터가 등장하게 되는 2010년경까지는 그러했습니다.
이미지 인식의 고성능 모델 등장, CNN 그리고 Alphago
2012년 AlexNet이라는 딥러닝 기반의 신경망구조(CNN:Convolutional Neural Networks)를 지닌 모델이 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)이라는 일반 사진에서 다양한 물체를 인식하는 유명한 이미지 인식 대회에서, 기존 인식기를 모두 따돌리고 압도적인 정확도로 승리합니다. 당시에는 이미지에서 어떤 불특정 한 물체를 인식해 내는 일은 사실상 제대로 된 전략이 없는 어려운 문제였습니다. 사진 속의 고양이를 보고, 그것이 고양이인지 개인지를 판단하는 문제가 얼마나 어려운 것인지 깨닫는 것은 그 인식기를 만드는 개발자가 되어보면 알 수 있게 됩니다. 사람은 대체 이 사진을 보고 어떻게 고양이라는 것을 알 수 있을지 아무리 고민하고 절차를 만들어도, 또 다른 해상도나 조명을 가진 기존 가정과 다른 고양이 사진을 만나면 여지없이 오류가 넘치게 됩니다.
그런데 수십 년 간 AI의 겨울기간에도 신경망 연구에 집중하며, 결과적으로 딥러닝 학습을 선도했던 토론토 대학의 Geoffrey Hinton 교수의 지도하에 해당 연구실 출신 Alex와 Ilya(현재의 OpenAI수석 과학자)가 이 AlexNet이라는 모델을 내놓습니다. GPU를 가지고 제법 큰 6천만 개짜리 파라미터를 지닌, 병렬처리로 계산한 신경망 모델로 기존 이미지 인식 모델을 모두 압도하게 됩니다.
그리고 이 즈음부터 AI연구는 이제 더 빠른 GPU와 더 많은 데이터, 그리고 특정 문제에 맞는 신경망 구조를 가진 싸움이 시작되었다고 볼 수 있습니다. 그리고 당시 이 싸움의 핵심 인물들과 회사는 Geoffrey Hinton 교수의 토론토 대학 랩 출신들과 Google이었습니다. Google은 이 분야에 선제 투자와 압도적인 자금력, 데이터, 컴퓨팅 파워, 인력으로 Google DeepMind까지 가세해 계속 AI를 발전시켜 나갔습니다. 2016년 AlphaGo는 이러한 딥러닝 발전의 상징적인 존재였죠. 강화학습이나 여러 가지 기술들, 그리고 다양한 구조의 모델 등이 있지만, 그 기저에는 늘 이 거대 신경망이 자리 잡고 있었습니다. 그리고 AlphaGo가 보여준 것은 특정 분야에서는 복잡해 보이는 문제라도 최고의 인간을 뛰어넘을 수 있다는 가능성입니다.
그렇게 Alphago는 분야를 한정하면, 연결주의로 모든 인간을 압도하는 AI의 유명 사례를 대중에게 명확하게 알린 셈이었습니다. 컴퓨터가 처음 고안되었을 때부터 시작된 기나긴 AI의 수많은 모델 간의 경쟁에서, 인간의 지능을 넘어서는 첫 문을 연 모델은, 위 Ilya Sutskever가 주장한 바로 “digital brain”, 거대 인공신경망이었던 것입니다. 그래서 지금도 더 큰 인공신경망을 향해 달리고 있는 셈입니다.
또한 이 AlexNet 등 이미지 인식에 특화된 CNN의 흥미로운 점은 그 입력값으로 이미지 전체를 받는다는 점입니다. 보통은 연구자들은 어떤 인식 문제를 위해서는 입력의 일관성 유지 혹은 예외를 축소하기 위해 이미지의 특정 영역만 잘라내고, 전처리를 하기 마련이지만 이 CNN은 연관 이미지의 전체 정보를 모두 넣으면 신경망이 알아서 필요한 영역에 집중해 판별하여 인식합니다. 즉 사람처럼 합니다. 이 모델은 일반적인 사람의 지능이 보여주는 예외에 대한 강건함이나 일반화 능력이 상당수 나타나는 것이 특징입니다.
기호주의로 만든 로직이나 프로그램들은, 그 원래 가정에서 벗어나면 엉뚱한 결과를 보여주었는데, 이 거대 신경망은 앤드류 응(Andrew Ng) 교수의 표현에 의하면, “깊게 고민하지 않는, 힐끔 보고 판단할 수 있는 문제들은 이제 딥러닝이 다 할 수 있다” 수준에 이르게 된 셈입니다.
그리고 이러한 딥러닝 기술은 이제 이미지 영역뿐만 아니라, sequence(시계열) 문제를 다루는 음성인식, 언어, 번역 등 다양한 분야로 전파되게 됩니다.
Transformer의 등장
2017년부터 2018년에는 그동안 이미지 영역이나 바둑 영역에서만 각광받은 대규모 신경망이 그 영역을 언어로 더욱 확장하게 됩니다. 2017년 Google이 발표한 “Attention is all you need”라는 논문을 통해 언어의 순차 처리, 즉 Sequence to Sequence(Seq2 Seq, 순차 데이터 변환)를 처리할 수 있는 Transformer구조가 공개되었습니다. Sequence라고 하면 순서가 중요한 데이터인데, 대표적인 것이 바로 “말” 즉 언어고, Sequence to Seqeunce의 대표적 문제는 바로 언어 번역입니다. 혹은 언어로 된 질문/답변이 될 수도 있습니다.
Transformer의 장점을 이해하려면 이 언어 Sequence 데이터를 처리하는 기존의 전통 방식을 이해해야 합니다. Transformer 이전에는 시계열 데이터는 순서대로 하나씩 입력하면서 처리하는 방식을 취했습니다. “나는 학교에 간다”를 처리하기 위해서는 차례차례 한 단어씩 집어넣어 계산했던 것이죠. 그러다 보니 한 문장을 처리하는 데 걸리는 속도가 느렸고, 긴 문장 속 입력 단어들이 많아지면, 맨 처음에 넣었던 데이터에 대한 고려가 대부분 약해진다는 단점이 있었습니다.
그러면 Transformer는 어떻게 한꺼번에 이 순차 데이터를 처리할까요? 데이터를 한꺼번에 넣고, 그것을 신경망으로 모두 처리하게 됩니다. 그러면 이제 순서와 특정 단어 간 연관도가 중요한 언어의 특성을 어떻게 반영할까요? 바로 단어 위치 정보(Positional Encoding)와 단어 간의 중요성을 모두 반영(Attention)하는 구조를 함께 부여합니다. 그리고 이 모든 것에는 거대 신경망이 합쳐져 있습니다. 이 구조만으로 지금의 ChatGPT의 모델이 된 Transformer의 기본 특징을 알 수 있게 됩니다.
간단히 요약을 해보겠습니다.
1) Transformer는 특정 문장을 입력받아 다른 문장으로 변환하는 거대 신경망입니다. 번역을 생각하면 가장 쉽습니다.
Ex> 나는 학교에 간다 -> I go to school
2) Transformer는 기존의 이러한 언어처리 모델들이 한 단어씩 처리하던 것을 한꺼번에 입력하도록 바꾸었습니다. “나는 학교에 간다”를 한꺼번에 넣을 수 있습니다. 그러면서 각 단어 간의 연관도를 같이 반영(Attention)하여 처리할 수 있게 되었습니다. 결과적으로 기존 순차처리 모델보다 속도가 빠르고 성능도 올라갑니다.
3) 이제 이 거대한 신경망을 대량의 텍스트 문장 데이터를 확보해 학습시키면, 언어문제의 여러 가지를 “마치 사람처럼 잘” 대응합니다.
여기서 용어 이해를 위해 문장의 단어를 구분하는 토큰(Token)이라는 개념에 대해 다루어보겠습니다. 기본적으로 인공 신경망은 앞서 퍼셉트론에서처럼, 입력을 모두 숫자 벡터로 받습니다(x1, x2,.. 를 생각해 보세요). 그런데 문장을 어떻게 숫자 벡터로 변환할까요? 방법은 우선 문장을 최소의 단어로 분할하고 각 단어별로 특정 숫자 벡터로 변환하는 것입니다. 이러면 숫자 벡터의 배열이 나오게 됩니다. 맨 먼저 문장을 분할하는 것부터 살펴보겠습니다. 예를 들어 국내 언어 모델은 한국어를 처리할 때면, 이 토큰은 주로 형태소 단위로 분할됩니다. 그것이 한국어의 최소 단위이기 때문입니다. 즉 아래와 같이 분절됩니다.
“나는 학교에 간다” -> “나|는| 학교|에|간|다”
그리고 이 각각의 형태소들은 기 언급된 지정된 미리 정해진 숫자 벡터로 변환됩니다. 따라서 언어 모델들은 모두 어떤 텍스트 문장을 입력받으면 정해진 기준의 토큰으로 분절되고, 그 토큰에 해당하는 정해진 벡터값을 부여받습니다. 그래서 실제로는 Transformer의 문장 입력은 위 단어들의 숫자 벡터 흐름(배열)입니다. 쉽게 말하면 2차원 배열이지요(각 단어별 n차원 벡터 * 단어 수 m개 = n*m 2차원 배열이 입력됩니다.)
“나” -> (0.12, 0.23, 0.52, 0.23, 0.34) …..
“는” -> (0.13, 0.22, 0.21, 0.21, 02) ….
….
이 벡터값을 부여하는 여러 가지 방법론이 있지만, 여기서는 그냥 비슷한 단어이면 비슷한 숫자 벡터가 할당된다고 이해할 수 있습니다. 그런데 이런 토큰화에 대해 해외 LLM들은 한글에 대해 아쉬운 점이 있습니다. 토큰 정의는 대규모 텍스트 데이터에서 자동으로 공통되어 나타나는 길이의 패턴을 파악해 정의하는 방법을 사용하는데(주로 Byte Pair Encoding이라는 방법 사용), 영어는 단어와 거의 일치되게 분절되지만, 한글 같은 외국어는 글자와 자모단위의 중간 어디 정도 수준으로 잘게 분할되도록 구성됩니다. 그래서 “나는 학교에 간다”를 GPT Tokenizer(토큰 분할기)로 분할해 보면 형태소 6개짜리 문장이 무려 21개의 토큰으로 나뉩니다. “I go to school”같은 경우 예컨대 4개 정도의 토큰으로 분할되는 것에 비하면 지나치게 잘게 분할됩니다.
따라서 GPT 학습 시 한글 데이터가 영어에 비해 부족한 부분과 이 한글 연관 토큰이 잘게 쪼개지는 것이 성능 저하의 한 원인이 될 수 있습니다. 최적화되지 않은 토큰은 낮은 성능과 정확도를 의미하기 때문입니다. 그리고 이는 국내 테크 회사들의 한글 맞춤형 LLM 모델들이 한글에 더 강점을 지닌다고 주장할 수 있는 근거가 될 수도 있습니다. 다만, 이렇게 작은 토큰으로 쪼개지면서도 ChatGPT가 좋은 성능을 가지는 것은 개인적으로는 인상 깊다고 생각하는 부분이 있습니다. 자모단위 정도의 유사 흐름으로 다음 토큰을 예상한다고 하면 얼마나 쉽지 않겠나 싶습니다.
여하튼 당분간 해외 LLM들의 토큰이란 영어에서는 단어, 한글에서는 자모단위의 분절 수준으로 생각하면 됩니다. 이를 잘 관찰할 수 있는 것은 실제 해당 서비스를 써보면 알 수 있습니다. ChatGPT의 출력 문자열의 흐름을 잘 보면 영어는 단어 단위로 빠르게 출력되는 데 반해 한글은 거의 자소 수준으로 느리게 완성되어 가는 모습을 보게 됩니다. 바로 위와 같은 이유 때문입니다.
Transformer 학습하기
Transformer는 내부적으로 Encoder와 Decoder로 나뉘는데, 각각을 단순히 설명해 보면, 입력받은 기준 문장을 구조화 및 추상화해서 이해하고(Encoder), 그것을 기반으로 번역을 한다든가 하는 구체적인 문장을 생성합니다(Decoder). 번역을 한다고 하면 번역을 하고 싶은 원 문장을 Encoder에 입력으로 넣고, Decoder에는 이제 처음부터 한 단어씩 번역문을 생성해나가면서, 출력된 단어를 다시 기존 번역문에 붙여서 한 단어씩 번역문을 늘려나가는 모습으로 작동합니다.
ChatGPT의 경우는 Transformer에서 Encoder부분을 떼고, Decoder부분에 집중해서 사용하는데, 이는 단어를 하나하나 붙여가면서 다음에 나올 가장 높은 확률의 단어가 무엇인지 알 수 있도록 출력하도록 하는 구조를 가지고 있습니다. 즉, Token들의 흐름을 입력받은 후 다음 Token으로 올 것들의 확률을 계산해 줍니다.
예를 들면 “I go to school and I ”이라고 입력하면 다음에 무엇이 올지 각 토큰별 확률을 알려줍니다. 아마도 “study”가 가장 높은 확률을 지니지 않을까요?
그렇게 ChatGPT의 GPT모델은 우리가 입력한 질문에 대한 답을 위해 끊임없이 그다음 단어(토큰)를 계산합니다. 그래서 한 단어씩 순차적으로 출력됩니다.
그런데 여기서 더 인상 깊고 흥미로운 부분은 이 Transformer를 학습시키는 전략입니다. 바로 Masking 학습이나 다음 단어 맞추기 전략인데요, 대량의 텍스트 문장을 가지고, 추출한 문장에서 빈칸을 맞추도록 하는 것(MLM:Masked Language Model)이 대표적입니다.
예를 들면, “나는 학교에 ___”에서 ___를 맞추도록 지속 학습시키는 방법입니다.
혹은 텍스트 데이터에서 한 문장과 다음 문장을 주고, 그것이 연결 문장이 맞는지 학습(NSP:Next Sentence Prediction)시키기도 합니다. 위의 모든 학습 방법은 텍스트 문장들만 있으면 별도 수기 분류 작업이 필요 없이 지정하여 학습이 가능합니다. 그리고 이렇게 하면 이 Transformer는 확보한 대량의 텍스트들을 놀랍게도 “이해하게” 됩니다. 이 과정에서 가장 중요한 장점은 언급한 대로 별도의 사람의 수기 분류 데이터가 필요 없다는 사실입니다. 대규모 신경망 학습은 거대한 데이터가 늘 필요한데, 수기 분류라는 고비용의 과정이 필요 없다는 점이 매우 중요합니다. LLM이 등장할 수 있었던 비밀 중의 하나입니다.
Transformer를 가지고 만든 Google-BERT(Bidirectional Encoder Representations from Transformers)가 이런 전략으로 학습합니다. 이 학습 전략을 BERT가 처음 사용한 것은 아니지만, 늘 이 대규모 학습문제에서 사람의 수기 분류한 데이터가 대량 필요한 어려움을 해결해 버렸습니다. (참고로, Google-BERT는 이 Transformer의 Encoder부분을 활용해 만든 언어모델입니다)
ChatGPT 같은 경우에는 그저 다음 단어를 맞추도록 학습하면 됩니다. 역시 대량의 문장 속에 다음 단어가 무엇인지 알고 있기 때문에, 가지고 있는 대규모 문장을 통해 반복적으로 학습시킬 수 있습니다. 그렇게만 해도 언어의 무언가 지식을 ChatGPT가 학습하게 되는 것입니다.
즉, 학습 전략을 대규모 텍스트 데이터로 진행하면, Transformer는 언어에 대한 기본 개념을 갖는 것으로 파악됩니다. 심지어 이런 것들이 추상화되어 신경망에 반영되면서 논리 추론도 가능하며, 복잡한 문제도 풀 수 있게 된다는 점이 점점 더 명확해지고 있습니다. 그러나 불행히도 구체적으로 신경망이 어떻게 그것을 가능하게 하는지는 여전히 명확하지 않습니다. 사람이 특정 뇌 영역에서 무엇을 전문적으로 담당하는 것 같은 효과, 예컨대 뇌에 사람의 얼굴을 인식하는 전담 영역이 있듯이, Transformer의 대규모 신경망에서 나타난다는 연구도 있긴 합니다. 하지만 아직 많은 것들이 알려지지 않았죠. 그러나 digital brain이 어떻게 작동하는지는 불명확하다고 하더라도, 예외에도 강하고 일반화 능력도 꽤 됩니다. 결국에는 digital brain의 불명확성은, 우리 생물학적 뇌에 대해 사람이 잘 이해하지 못하는 상황과도 비슷합니다. 둘 다 이해를 명확히 하지는 못했으나 모두 괜찮은 성능을 보여줍니다. 개인적으로는 오히려 이 연결 가중치가 모두 알려진 digital brain을 신경과학자들이 연구하면, 생물학적 뇌의 비밀을 풀 수 있는 게 아닌가 상상하기도 합니다.
그리고 기술적으로 더 유용한 것은 이 Transformer의 앞뒤에 신경망 레이어를 추가로 붙여서 다목적으로 쓸 수 있다는 점입니다. 학습이 끝난 Pre-training Google-BERT에 출력부를 변형하여, 문장을 넣었을 때 긍부정으로 판정한다든가, 두 문장이 관계있는지를 묻는다든가 변환이 가능합니다. 그렇게 구조를 조금 바꾼 후 비교적 적은 수의 데이터로 추가 학습(Fine-tuning이라고 한다)을 하면, 기존의 해당 목적 전용으로 설계된 모델보다 더 높은 성능을 발휘하는 것입니다. 어지간한 언어 모델 문제를 해결하기 위해 수기 분류 데이터가 엄청나게 많이 필요한데, 이 문제를 이렇게 문장만으로 엄청나게 학습시키고, 소규모 튜닝만으로 처리하는 비교적 우아한 방법을 찾아낸 셈입니다. 그래서 이 Pre-training Model을 Foundation Model이라고 부릅니다. 아래가 비유적인 실제 예가 됩니다.
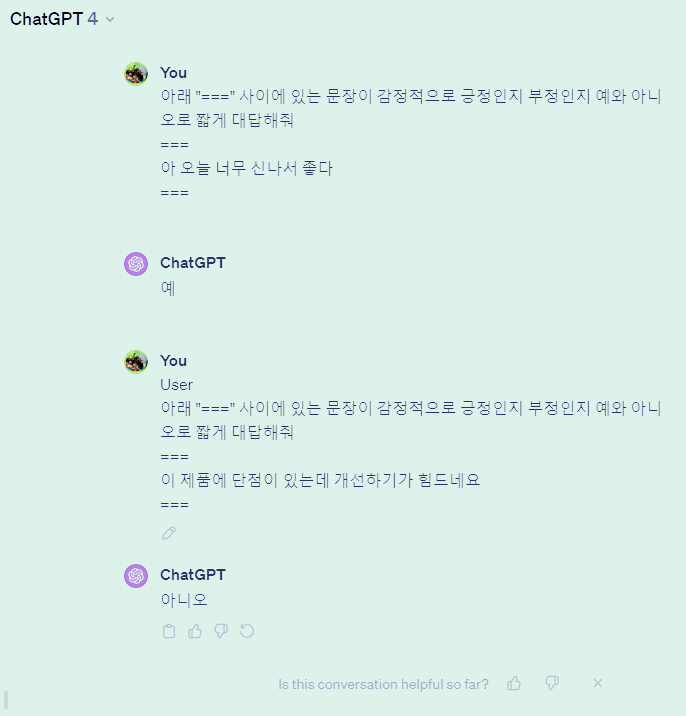
수기 분류 없이, 대량으로 모으기만 한 문장들로 신경망 모델을 학습하고 나서, 조금의 수기 분류된 질문/답변 데이터만 추가로 넣어주면, 질문/답변 AI가 나타나는 것입니다. 그렇게 2018년 처음 Google-BERT가 발표 및 완전 공개되고, 기존 언어모델이 각각 풀던 이런 긍부정, 질문/답변, 연관 문장 맞추기 등 모든 문제에서 모두 SOTA(State of The Art)를 찍게 됩니다. 그 모든 분야에서 최고의 모델이 된 것이지요. 필자도 그때 처음 돌려보았을 때의 감격이 기억납니다. 하나로 모든 것을 해결하다니, 만능 AI 같은 것이었고, 외계 기술 같은 느낌이었습니다.
이러한 Fine-tuning 전략은 무언가 언어의 기본을 이해하는 모델(Foundation Model)에 기반하여, 적은 비용으로 더 확장할 수 있는 매력이 있습니다. 대규모 텍스트 데이터로 학습한 BERT 모델을 Google이 공개했었으므로 가능성이 무궁무진했었죠. 그리고 이 특성은 이후에도 이어집니다.
GPT가 달려온 길
GPT는 앞서 밝힌 대로 Transformer의 Decoder부분을 응용한 모델입니다. 이 모델은 어떤 입력된 문장의 다음 토큰을 맞추는데 특화되어 있습니다. 그런데 OpenAI는 기존과 차원이 다른 신경망 크기로 이것을 상용화했습니다. Google이 AI 세상을 지배할 줄 알았는데, 의외로 OpenAI가 대박을 터뜨린 셈입니다. ChatGPT로 서비스한 모델인 GPT-3는 175B(Billion) 즉 1,750억 개 파라미터(연결 가중치)를 지닙니다. 예상되는 수백억 원대의 학습 비용을 생각해 보면 이렇게 도전해 나가는 의사결정이 쉽지 않았을 것입니다. 하지만 그들은 더 큰 신경망으로 더 좋은 데이터로 학습하면 인상적인 답변을 할 수 있다는 것을 깨달았습니다. 인터뷰를 보면 OpenAI가 처음부터 이렇게 거대하게 만들 생각이 있는 것은 아니었습니다. MS로부터 받았던 거대 투자도 클라우드 사용료였다고 합니다. 처음에는 여러 가지 시행착오를 거치다가, 기존과 완전히 차원이 다른 수준의 거대 신경망으로 가닥을 잡아 발전시켰던 것이지요. Transformer를 발표했던 AI 거인 Google을 따돌린 원동력이 되었을 겁니다. 물론 그 중간중간의 여러가지 노하우가 있었겠지만 말입니다.
이 1,750억 파라미터의 크기를 가늠하기 위해 사람의 뇌를 살펴봅시다. 인간의 신경세포의 수는 1천억 개로 알려져 있고, 각 신경세포별로 1천~1만 개 정도로의 연결이 되어 있다고 추정됩니다. 따라서 사람의 뇌에는 적게 잡아서 100조 개의 연결이 있을 것이라 예상됩니다. 결국 10T(Trillion) 개의 파라미터가 인간의 뇌라고 볼 수 있죠. 175B는 이 10T의 2% 정도 되는 연결개수입니다(하지만 뇌 전체 대비해서 GPT-3가 언어에만 집중한다고 생각하면 그렇게 적지 않을 수 있습니다). 모델 파일 용량으로 표현해 보면, 오픈소스 LLAMA 2의 70B모델 파일의 크기가 130GB 정도 되므로, 175B 면 325GB 정도 된다고 유추해 볼 수 있습니다. 0.3TB 정도의 파일이면 현재의 GPT-3 정도의 디지털 뇌를 준비시킬 수 있게 됩니다.
GPT는 이렇게 Pre-training 된 모델에 몇 가지 더 추가로 학습합니다. RLHF(Reinforment Learning from Human Feedback)가 대표적으로 알려진 단계로 앞서 Google-BERT의 Fine-tuning과 유사합니다. Pre-training 이후 특정 목적에 맞게 추가학습을 하는 것입니다. 이 경우에는 질문/답변이 됩니다. 역시 훨씬 더 적은 데이터로도 목적을 달성하는 것을 보여주었습니다.
이후에 GPT는 모델의 크기를 계속 키우고. 아마 다양한 Fine-tuning전략을 시행하거나 Transformer모델을 개선시킬 수도 있을 겁니다. 더 고품질의 데이터를 넣을 수도 있습니다. GPT가 다양한 목적으로 사용되는 이유도 이러한 Transformer의 학습 방법에 기인한, Pre-training과 Fine-tuning전략이 가능하기 때문입니다.
이렇게 Transformer는 기본적으로 언어와 지식에 대한 Pre-training에 기반하여 더 많은 변형 업무를 수행할 수 있습니다. 예컨대 이 Transformer는 기존에 수기 분류해야 했던 학습 데이터 일부를 1차 자동 분류하는 업무를 수행할 수도 있죠. 따라서 아직도 발전 가능성은 무궁무진합니다.
지금까지 살펴본 대로, 연결주의 입장에서 보면, 계속 신경망의 크기를 키워나갈 수 있고, 이를 위한 하드웨어는 계속 발전하고 있습니다. 앞서 언급했듯이 GPT를 이용해 데이터를 더 정비하거나 학습을 가속화할 여러 가지가 가능합니다. GPT가 생성한 질의응답 데이터를 이용해 학습 데이터로 삼아 Meta의 오픈소스 LLM인 LLAMA를 튜닝한 이야기도 유명합니다(Alpaca). GPT가 더 작은 모델들의 선생님 역할을 할 수도 있는 것입니다.
과연 텍스트 데이터로 pretrain 한 모델(Foundation Model)과 Fine-tuning만으로 GPT는 향후 얼마나 자연스러운 대답을 할 수 있을까요? 이에 대해 AGI(Artificial General Intelligence, 범용 인공지능)가 가까이 있다고 주장하는 이들은 지금 투자속도와 글로벌 연구 협업이면 몇 년 안에 가능하다고 말하고 있습니다. 연결주의자 입장에서는 이미 뇌와 유사한 구조의 신경망이 학습 가능하며, 이미 뇌와 유사한 수준으로 작동하고 있기 때문에, 더 큰 신경망으로 연산과 데이터만 추가되면 AGI가 되지 않을 이유가 없어 보이는 것입니다. 그러나 이 부분은 각 특성별로 좀 더 발전방향을 두고 보아야 할 문제입니다. 지금의 대량의 문장과 Transformer, 큰 신경망만으로 과연 그것이 가능할까요? 연결주의의 단점은 거대 신경망을 블랙박스로 놓기 때문에, 정확한 이론적인 예측을 하기가 어렵습니다. 그래서 오히려 막연한 거품이 생기기도 쉽습니다. 그래서 늘 전문가들 사이에서도 이 긍정론과 부정론이 공존합니다. 그러나 최근 1년간 AGI에 대한 기대가 커진 것은 명확한 사실입니다.
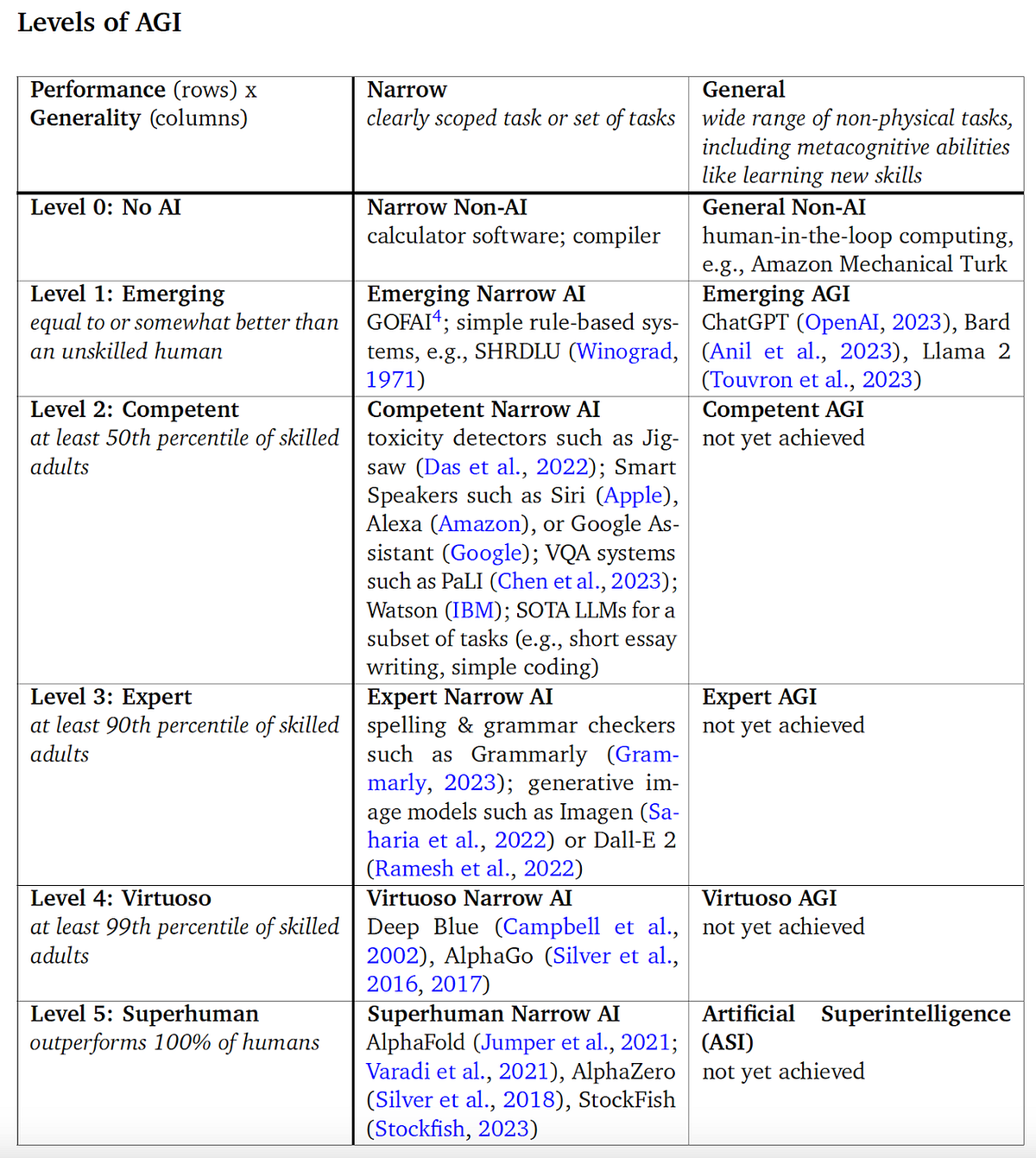
구글 딥마인드 연구진은 최근 발표에서 AGI의 수준을 0~5 레벨로 나누고, 특정한 분야에 한정하면 이미 Superhuman을 달성했다고 주장합니다. 그러나 일반적인 분야에서는 Level1 정도만 달성했다고 평가하고 있습니다. Level2가 달성되면 일반 숙련된 성인의 50%를 대체하는 정도이고 Level3 면 90%를 대체하게 됩니다. 이 정도 수준에 이를 수 있다면 사회적인 파급 효과는 엄청날 수 있다고 볼 수 있습니다. 여하튼 향후 수년 안에 인간 수준의 신경망과 더 크고 정비된 데이터, 더 빨라진 하드웨어를 가지고 그 질문에 답을 줄 수 있을 것이라 보고 있습니다.
ChatGPT 미래는 어떻게 전개될까요?
‘23.11월 초 개최된 OpenAI의 개발자 행사에서, 이제 사람이 하는 일을 70% 정도의 완성도로 하는 일은 ChatGPT에 맡길 수 있다는 이야기가 나온 것 같습니다. 개인적으로 경험해 본 GPT-4의 성능도 인상 깊습니다. 늘 한국어에 대한 성능이, 아직 직원이 수백 명 정도밖에 되지 않는 수준인 OpenAI에서 이 정도로 달성가능하다는 게 놀랍습니다. 다양한 작업이나 질문에 대해 깊이 있는 의견 제시를 다국어로 광범위하게 해주고 있습니다. if/then 같은 논리를 잔뜩 부여한 것이 아니라 Foundation Model이 Fine-tuning을 통해 대부분 처리해주고 있음을 암시합니다. 답변의 수준을 보면 Foundation Model 성능이 좋지 않고서는 도저히 불가능한 것들이 많습니다.
메타의 LLAMA 2 공개에 이은 오픈소스의 추격도 거셉니다. 더 작은 모델로 더 높은 성능을 달성하려는 노력도 계속되고 있습니다. 금융권에 있어서 이 공개형 모델이 중요한 것은 현재 ChatGPT의 자체 API 서비스가 망분리 정책에 적합하지 않은 부분이 있는 점입니다. 따라서 On-prem이나 기존 사용 중인 Major CSP(클라우드 공급자)에 연계되어 규제 환경하에 사용 가능한 주요 LLM 모델 회사들의 B2B 형태에도 지속 관심이 필요합니다. Microsoft가 OpenAI와의 투자 계약(MS의 선적용권)에 의해 자사 Azure에 OpenAI Service(B2B)를 출시 및 진화시키는 것도 그래서 지속 지켜볼 필요가 있습니다.
그리고 ChatGPT의 GPTs는 매우 인상 깊습니다. 앞서 밝혔듯이 AGI가 달성되는 것은 좀 더 지켜봐야 하겠지만, 특정 분야에 집중하면 전문가를 넘어설 수 있습니다. 그러면 각 전문가에 특화된 ChatGPT(Assistant 혹은 Agent, 여기서는 GPTs)가 출현하리라는 예상을 손쉽게 할 수 있고, OpenAI는 그 시장을 선점하는 모양새입니다. 최고성능의 LLM을 보유하며 각각 튜닝하여 더 높은 성능의 전문화된 챗봇을 만들 수 있다면 얼마나 매력적일까요? 각 사들도 그렇게 튜닝한 모델을 최적화해서 서비스할 테고, 일반 사용자들은 해당 전문적으로 튜닝된 Assistant를 가져다 쓰면 됩니다.
다양한 플러그인과 이미지 생성으로의 확장(DALL-E 3)도 매력적입니다. 최근 발표에서 이야기한 이해할 수 있는 최대 입력 토큰의 길이 확장도 그렇습니다. 기존 4K(4096개) 토큰보다 훨씬 더 긴 128K 토큰의 과거 대화에 기반하여 이야기할 수 있습니다. 이제 사실 대화가 아니라 책을 한 권 넣어도 모두 참조해 답변을 할 수 있게 됩니다. 너무 세분화된 토큰으로 분할되는 한글 관점에서는 더 다행입니다. 기존 4K 토큰 길이면 한글 1.5천 글자 정도를 간신히 넘는 수준이었기 때문입니다. 아마도 처리할 토큰이 길어지면 성능은 떨어지겠지만 그래도 아예 반영하지 못하는 것보다는 나을 겁니다.
또한, 시장의 생성형 AI 진화의 방향은 멀티모달(텍스트뿐 아니라 영상, 이미지 등 복합)로 보고 있습니다. ChatGPT앱의 음성 대화형 인터페이스 지원도 인상적입니다. 집에서 사용하던 구글 AI 스피커가 그저 음악 플레이용이라면 이 ChatGPT 음성 인터페이스는 다양한 대화를 나눌 수 있는 수준입니다. GPT-4가 더 업그레이드되고 속도가 개선되면 얼마나 더 활용성이 커질까 기대되는 부분이 있습니다.
LLM의 역사 마무리
지금까지 빠른 속도로 전체 모습이나 여정을 살펴보았습니다. 연결주의로 이어진, 대규모 신경망에 기반한 모델은 2010년대에 들어 처음으로 사람을 능가하는 모습을 보여주었고, 2016년 AlphaGo에 이어 2022년 12월부터는 언어모델의 형태로 일반인의 삶에까지 ChatGPT라는 이름으로 다가왔습니다.
더 큰 모델은 더 빠른 대용량의 하드웨어 발전에 의해 아직도 나아지고 있습니다. LLM 연관 빅테크들에 대한 투자도 그렇지만, GPU도 더욱 대규모화될 것입니다. 그동안 수년간 계속 유례없는 투자가 되고 있다고 주장했었는데, 올해는 전 세계가 투자하는 느낌입니다. 이미 MS, Google, Meta, Amazon의 내외부 투자뿐 아니라, 국내외 회사들의 이 분야에 대한 투자를 보면 말 그대로 “LLM 붐”이라고 말할 수 있습니다. 더군다나 데이터도 더 고품질의 더 많은 텍스트들이 추가되며, 이후 Fine-tuning을 위한 수기 데이터도 더 확장될 것입니다.
개인적으로는 이 LLM이 특정 분야에 대해서는 1~2년 안에 최소한 인간 전문가 수준의 품질을 내는 분야가 꽤 늘어날 것이라고 생각합니다. AGI가 모든 분야에서 사람이 원하는 100%에 다가가려면 얼마나 걸릴지는 긍정과 부정이 혼재하지만, 분야를 매우 한정하면 어지간한 사람만큼 곧바로 결과를 낼 수 있을 것은 분명해 보입니다. 그리고 또 다른 방식의 연구가 급진전해서, AGI가 더 당겨질 수 있겠습니다.
따라서 이 분야에 대한 관심과 적용 노력은 최소한 그 한계가 확인되기 전까지는 충분히 진행해야 한다고 생각합니다. 발전속도가 가파릅니다. 2023년 지난 한 해가 이 분야를 관심 있게 보아온 사람 대부분에게 지난 십 년이 넘는 기간보다 더 빠르게 지나온 느낌일 것이라 생각합니다. 내년도 충분히 그러한 시간을 보내게 되지 않을까요.
그러면 이제 마무리하고, 다음으로 금융사에서는 이러한 흐름에 어떻게 대응하면 좋을지를 살펴보겠습니다.
케이뱅크와 함께 하고 싶다면 🚀
'Tech' 카테고리의 다른 글
| 케이뱅크 이상거래탐지시스템 Singlestore DB 도입기 (0) | 2023.12.05 |
|---|---|
| 생성형AI/LLM/ChatGPT의 짧은 역사와 이해 그리고 금융 적용 - 2부 (0) | 2023.12.01 |
| 딥러닝(Deep Learning) 기반 개인화 추천시스템 (0) | 2023.11.15 |
| 얼굴 탐색 속도 높이기 : 벡터 데이터베이스의 이해 및 활용 (feat. Chroma) (0) | 2023.11.13 |
| Application Modernization-MSA (0) | 2023.09.06 |