
2025. 5. 2.ㆍTech

안녕하세요!
케이뱅크 데이터AI서비스팀에서 AI/ML 업무를 맡고 있는 최고운입니다.
오늘은 제가 최근 관심을 갖고 활용하고 있는 LLM 프레임워크인 DSPy에 대해 소개해 드리고자 합니다.
목차
- 들어가며
- LangChain vs. DSPy
- DSPy 실전 사용법
- 마치며
들어가며
LLM 프레임워크란?
대형 언어모델(LLM)을 활용한 애플리케이션을 더 쉽고, 체계적으로 설계·구현·운영할 수 있도록 지원하는 소프트웨어 구조와 도구들의 집합을 의미합니다.
ChatGPT, Claude, Gemini 등 다양한 LLM을 잘 활용하기 위해 좋은 프롬프트를 작성하는 것이 필수라는 것은 이제 상식처럼 여겨지고 있습니다.
저 역시 LLM Application 개발을 하며 프롬프트 엔지니어링에 많은 시간을 투자해야 했는데요, 프롬프트를 매번 수작업으로 수정하고 테스트하는 과정이 때로는 상당히 비효율적으로 느껴지곤 했습니다.
프롬프트 작성에 대한 가이드라인은 존재하지만
- 어느 정도까지 구체적으로 설명해야 하는지,
- 예시는 몇 개를 제시해야 하는지,
- 그리고 어떤 예시가 효과적인지에 대해서는 여전히 명확한 기준이 없습니다.
특히, 프롬프팅 과정에서 작성 방식과 응답 결과를 정량적으로 분석하고 이를 체계적으로 개선하는 작업은 지금도 쉽지 않은 과제로 남아 있습니다.
이러한 고민을 덜어줄 수 있는 프레임워크가 바로 DSPy입니다.
DSPy는 프롬프트 최적화, 평가 작업을 자동화하여, 보다 정확하고 일관된 LLM 응답을 생성할 수 있도록 지원합니다.
이러한 강력한 장점 때문에, 저는 최근 진행 중인 업무에 DSPy를 적극 활용하고 있습니다.
LangChain vs. DSPy
LLM 프레임워크 중 가장 대중적으로 알려진 LangChain과 오늘 소개할 DSPy를 비교해보면서, DSPy의 특징을 더 구체적으로 살펴보겠습니다.
| DSPy | LangChain | |
| 출시일 | 2022.12 | 2022.10 |
| 프롬프트 처리 | 프롬프트 자동 최적화 | 수동 프롬프트 엔지니어링 |
| 강점 | 자동 최적화로 성능/안정성 향상 복잡한 파이프라인 구축 용이 |
방대한 통합 기능 (DB, API, 벡터 스토어 등) 유연한 체인 구성 |
| 생태계/커뮤니티 | 상대적으로 작은 커뮤니티 관련 정보 찾기 어려움 |
크고 활발한 커뮤니티 방대한 관련 문서 |
| 적합한 프로젝트 | 복잡한 다단계 추론 파이프라인, 성능/안정성 자동 최적화가 중요한 경우 |
다양한 외부 도구/데이터통합이 중요하고, 유연한 구성이 필요한 경우 |
LangChain은 외부 데이터베이스, 벡터스토어, 클라우드 서비스와 손쉽게 연동할 수 있어, 빠르게 다양한 LLM 기반 애플리케이션을 구축해야 할 때 매우 유리합니다.
또한, 커뮤니티도 활발하고 참고할 수 있는 자료가 풍부해 학습과 개발이 비교적 수월합니다.
반면, DSPy는 외부 도구와의 통합보다는 LLM의 '응답 품질'을 높이는 데 집중합니다.
프롬프트를 수동으로 튜닝하는 수고를 줄여주기 때문에 개발자는 더 본질적인 애플리케이션 로직에 집중할 수 있습니다.
DSPy 실전 사용법
AI 엔지니어이거나 데이터사이언티스트라면, 딥러닝 프레임워크인 PyTorch와 어느 정도 친숙하실 텐데요.
DSPy는 PyTorch의 구성 철학과 스타일에서 영감을 받아 설계된 프레임워크입니다.
그렇기 때문에 PyTorch를 사용해 보셨다면 DSPy의 모듈 기반 구조도 쉽게 이해할 수 있습니다.
DSPy는 프롬프트 최적화뿐 아니라 RAG, Agent 구성까지 지원합니다.
오늘은 프롬프트 최적화에 중점을 두어, 지시문을 기반으로 간단한 수학 문제를 해결하는 LLM App을 구현하며 DSPy의 사용법을 소개해드리겠습니다.
구현 시 활용할 LLM은 OpenAI의 GPT4o-mini 모델입니다.
먼저 개발을 위한 conda 가상환경을 생성해 활성화한 후, DSPy 패키지를 설치하겠습니다.
conda create -n math_qa python=3.11
conda activate math_qa
pip install -U dspy
이제 사용할 LLM을 로드하겠습니다. OpenAI 모델 사용을 위해서 사전에 API KEY를 발급받아주세요!
또는 로컬에 구축되어있는 LLM 모델을 활용하는 것도 가능합니다. 해당 방법은 공식 Documentation을 참고해주세요!
import dspy
import os
OPEN_API_KEY = os.getenv('OPEN_API_KEY')
model = dspy.LM(model="gpt-4o-mini", api_key=OPEN_API_KEY, temperature=0)
dspy.settings.configure(lm=model)DSPy를 통해 자동 프롬프트 최적화를 수행하기 위해서는 몇 가지 핵심 기능들을 정의해야 합니다.
바로 Signature, Module, Optimizer입니다.
Signature
LLM의 입력과 출력을 정의하는 부분
기존에는 프롬프트를 작성할 때, 입력과 출력을 설명하기 위해 긴 설명문을 작성하고 예제를 추가해야 했습니다.
예컨대 이런 식으로 프롬프트를 작성해야 했을 겁니다. Task에 대해 명확하고 구체적으로 요구할수록 응답의 품질이 좋은 경향이 있기 때문에 엔지니어에 따라 응답의 품질과 결과가 많이 달라질 수 있죠.
# 역할
당신은 학생들이 이해하기 쉽게 수학 문제를 풀이하는 수학 선생님입니다.
# 요구사항
제시된 수학 문제 지시문을 읽고 풀이 과정을 단계적으로 설명하고 최종 답을 제시하세요.
# 입력 예시
1에서 3을 뺀 후, 6을 곱하세요.
# 출력 예시
1단계: 1 - 3 = -2
2단계: -2 × 6 = -12
-12
이번 예시와 같이 간단한 Task에 대해서는 큰 힘을 들이지 않고 프롬프트를 작성하더라도 어느 정도 원하는 형식대로 잘 응답하지만, 요구사항이 복잡해지고 원하는 입출력 형태가 명확할수록 더욱 길고 자세한 프롬프트를 작성해야 하고 만족스러운 결과가 나올 때까지 프롬프트를 직접 수정해야 합니다.
DSPy에서는 입출력 항목을 변수로 명확하게 정의하고, 각 변수에 대해 간단한 Description만 추가함으로써 입력과 출력을 구조화할 수 있습니다.
class MathQASignature(dspy.Signature):
"""주어진 수학 지시문에 대해 풀이 과정을 설명하고 최종 답을 응답"""
instruction = dspy.InputField(desc="수학 문제에 대한 지시문")
reasoning_steps = dspy.OutputField(desc="풀이 과정")
final_answer = dspy.OutputField(desc="정답")InputField와 OutputField로 모델의 입력과 출력을 구분합니다. 각 변수에 대한 설명을 추가함으로써 원하는 방향으로 응답을 받을 수 있도록 가이드를 제공할 수 있습니다.
수학 문제 풀이 LLM 애플리케이션 개발을 위해서 수학 문제를 한국어로 지시하는 instruction 입력 변수를 정의하고, 입력 문장을 기반으로 풀이 과정을 설명하는 reasoning_steps 변수와 최종 답을 응답하는 final_answer 변수를 정의했습니다.
Module
응답 생성을 위한 과정 및 방법을 정의하는 부분
응답을 생성하는 과정에서 활용할 수 있는 기법들이 다양하게 등장하고 있습니다. 예를 들어, 추론적 사고를 가능케 하는 프롬프팅 방법인 사고의 사슬(Chain Of Thought), 외부 지식을 활용해 응답 정확도를 높이는 RAG(Retrieval-Augmented Generation)가 있습니다.
DSPy에서는 이러한 응답 생성 과정을 정의할 수 있는 Module이라는 개념이 존재합니다.
Pytorch에서 모델의 아키텍처를 정의하는 형식과 유사한 형식으로 LLM의 응답 방법을 정의할 수 있습니다.
class GenerateAnswer(dspy.Module):
def __init__(self):
super().__init__()
self.CoT = dspy.ChainOfThought(MathQASignature)
def forward(self, instruction):
prediction = self.CoT(instruction=instruction)
return dspy.Prediction(
reasoning_steps=prediction.reasoning_steps,
final_answer=prediction.final_answer
)수학 문제를 틀리지 않고 잘 풀 수 있도록 DSPy의 ChainOfThought를 활용하여 추론적 사고를 통해 응답을 하도록 정의했습니다.
앞서 정의한 입력 변수를 입력으로 제공했을 때, reasoning_steps와 final_answer라는 출력 변수로 응답 결과가 저장되도록 아키텍처를 구성했습니다.
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits앞서 DSPy의 Module 정의 방식이 Pytorch의 모델 아키텍처 정의 방법과 유사하다는 언급을 했었는데요, 위 코드는 Pytorch로 간단한 뉴럴 네트워크를 구성한 예시입니다. 어떤가요? 꽤 비슷하죠? 😋
*출처 : https://pytorch.org/tutorials/beginner/basics/buildmodel_tutorial.html
predictor = GenerateAnswer()
prediction = predictor(instruction="(3-5)*3+1=?")
print("Reasoning Steps:", prediction.reasoning_steps)
print("Final Answer:", prediction.final_answer)
# Reasoning Steps: 1. 괄호 안의 연산을 수행합니다: 3 - 5 = -2
# 2. 그 결과를 3과 곱합니다: -2 * 3 = -6
# 3. 마지막으로 1을 더합니다: -6 + 1 = -5
# Final Answer: -5이 단계까지 진행이 되었다면, 프롬프트 최적화를 진행하지 않더라도 LLM으로부터 응답을 얻고 그 결과를 LLM Application 개발에 활용할 수 있습니다.
LLM에게 수학 문제를 풀도록 지시해 보았습니다. 초기 응답을 확인하니, 단계별 풀이 과정(reasoning_steps)에 설명과 같은 자연어가 섞여 나오는 것을 확인할 수 있습니다.
저는 reasoning_steps가 오직 숫자와 연산자, 그리고 정해진 형식("1단계: 1 + 1 = 2")으로만 구성되기를 원합니다. 이를 위해 DSPy의 Signature를 수정하고, 프롬프트 최적화를 수행하여 LLM이 원하는 형식과 정확도를 갖춘 응답을 일관되게 생성하도록 만들어 보겠습니다.
1단계: Signature Description 수정
가장 먼저 시도해 볼 수 있는 방법은 Signature의 출력 desc에 원하는 형식을 명확하게 명시하는 것입니다.
class MathQASignature(dspy.Signature):
"""주어진 수학 지시문에 대해 풀이 과정을 설명하고 최종 답을 응답"""
instruction = dspy.InputField(desc="수학 문제에 대한 지시문")
reasoning_steps = dspy.OutputField(desc="풀이 과정. '1단계: 1 + 1 = 2\n'와 같은 형식으로 작성")
final_answer = dspy.OutputField(desc="정답")
# Reasoning Steps: 1단계: 3 - 5 = -2
# 2단계: -2 * 3 = -6
# 3단계: -6 + 1 = -5
# Final Answer: -5이렇게 reasoning_steps 필드의 desc에 구체적인 형식 예시를 추가함으로써 이전보다 원하는 형식에 맞게 출력이 개선되었습니다.
2단계: 프롬프트 최적화의 필요성 및 Optimizer 소개
Optimizer
프롬프트 최적화 또는 모델 가중치 미세 조정을 위한 모듈
하지만 LLM은 동일한 입력에 대해서도 항상 같은 방식으로 응답하지 않을 수 있습니다. 응답의 일관성을 높이고 정확도를 더욱 개선하기 위해, DSPy의 핵심 기능인 프롬프트 최적화를 진행해 보겠습니다.
DSPy는 프롬프트 최적화를 위한 다양한 Optimizer 모듈을 제공합니다. Optimizer는 우리가 정의한 프로그램(모듈과 시그니처)을 입력으로 받아, 더 나은 성능을 내도록 프롬프트(내부 지시사항 및 예제 포함)를 자동으로 조정해 주는 강력한 도구입니다. 주요 Optimizer들은 다음과 같습니다.
| 종류 | 동작 원리 | 추천 사용 경우 |
| LabeledFewShot | 사용자가 입력한 예제들 중에서 무작위로 k개를 선택 | 가장 간단한 Few Shot 방식 |
| BootstrapFewShot | 사용자가 입력한 예제들을 바탕으로 고품질 예제를 생성하고 메트릭을 통과한 예제들을 사용 | 예제의 개수가 매우 적은 경우(약 10개) |
| BootstrapFewShotWithRandomSearch | BootstrapFewShot을 여러번 수행해 다양한 예제 조합 생성 후 가장 성능이 좋은 조합을 찾음 | 예제가 약 50개 이상인 경우 |
| KNNFewShot | 입력과 가장 유사한 예제 k개를 탐색 후 BootstrapFewShot 수행 | 입력에 따라 동적으로 가장 관련 높은 예제를 선택하고자 하는 경우 |
| COPRO | 프롬프트의 설명문을 자동 개선, 즉 Signature를 개선 | 설명문을 최적화하고자 할 때 |
| MIPROv2 | 베이지안 최적화를 통해 프롬프트의 설명문과 예제를 모두 최적화 | Zero Shot으로 시작하거나 예제가 200개 이상인 경우 |
이번 예제에서는 초기 결과가 어느 정도 괜찮고, 사용할 예제 데이터가 많지 않으므로 BootstrapFewShot 옵티마이저를 선택하여 프롬프트에 포함될 예제를 최적화해 보겠습니다(설명문/지시사항은 최적화 대상에 포함되지 않습니다).
이를 위해 먼저 학습 데이터셋(trainset)과 검증 데이터셋(devset)을 준비해야 합니다.
- trainset: Optimizer가 좋은 Few-shot 데모를 생성하고 선택하는 데 사용됩니다.
- devset: 최적화가 완료된 프로그램의 최종 성능을 평가하는 데 사용됩니다.
trainset = [
dspy.Example(
instruction="7과 8을 곱한 뒤, 5를 더하세요.",
reasoning_steps="1단계: 7 × 8 = 56\n2단계: 56 + 5 = 61",
final_answer="61"
).with_inputs("instruction"),
dspy.Example(
instruction="15에서 9를 뺀 다음, 4를 곱하세요.",
reasoning_steps="1단계: 15 - 9 = 6\n2단계: 6 × 4 = 24",
final_answer="24"
).with_inputs("instruction"),
dspy.Example(
instruction="6을 세 번 더한 값에 2를 곱하세요.",
reasoning_steps="1단계: 6 + 6 + 6 = 18\n2단계: 18 × 2 = 36",
final_answer="36"
).with_inputs("instruction"),
dspy.Example(
instruction="12를 3으로 나눈 뒤, 거기에 7을 더하세요.",
reasoning_steps="1단계: 12 ÷ 3 = 4\n2단계: 4 + 7 = 11",
final_answer="11"
).with_inputs("instruction"),
dspy.Example(
instruction="5와 9를 더한 다음, 그 결과에 2를 빼세요.",
reasoning_steps="1단계: 5 + 9 = 14\n2단계: 14 - 2 = 12",
final_answer="12"
).with_inputs("instruction"),
]
devset = [
dspy.Example(
instruction="9와 4를 더한 뒤, 6을 곱하세요.",
reasoning_steps="1단계: 9 + 4 = 13\n2단계: 13 × 6 = 78",
final_answer="78"
).with_inputs("instruction"),
dspy.Example(
instruction="20을 5로 나눈 다음, 3을 더하세요.",
reasoning_steps="1단계: 20 ÷ 5 = 4\n2단계: 4 + 3 = 7",
final_answer="7"
).with_inputs("instruction"),
dspy.Example(
instruction="10에서 3을 뺀 후, 그 결과를 2로 나누세요.",
reasoning_steps="1단계: 10 - 3 = 7\n2단계: 7 ÷ 2 = 3.5",
final_answer="3.5"
).with_inputs("instruction"),
]이와 같이 학습용 예제 5개와 검증용 예제 3개를 구성했습니다.
머신러닝 또는 딥러닝 모델의 성능을 평가하기 위해 어떠한 메트릭을 사용할 것인지 결정하는 것이 중요하듯이, 프롬프트 최적화를 위해서도 평가 메트릭을 정의하는 것이 필요합니다.
메트릭은 어떤 결과가 '좋은' 결과인지를 판단하는 기준이 되며, Optimizer는 이 메트릭 점수를 최대화하는 방향으로 프롬프트를 조정합니다.
DSPy는 몇 가지 내장 메트릭을 제공합니다.
| 종류 | 동작 원리 |
| answer_exact_match | example과 pred의 문자열이 정확히 일치하는지를 검사 |
| answer_passage_match | example의 특정 문자열이 pred에 포함되는지를 검사 |
| SemanticF1 | LLM을 활용한 자동 평가. 답변의 내용적 유사성을 평가한 의미론적 F1 Score |
| CompleteAndGrounded | LLM을 활용한 자동 평가. 응답 결과가 예제의 질문 및 지시사항을 잘 반영하는지, 문맥이나 근거에 충실한지 검사 |
이번 예제에서는 (1) 최종 답변의 정확성과 (2) 풀이 과정 형식의 준수 여부를 성능 평가의 기준으로 세우고자 합니다. 내장 메트릭들을 사용할 수도 있지만 LLM을 활용한 자동 평가 메트릭을 직접 정의해 보겠습니다.
from dspy.teleprompt import BootstrapFewShot
class Assess(dspy.Signature):
"""모델의 응답을 평가"""
assessed_text = dspy.InputField(desc="평가 대상")
assessment_question = dspy.InputField(desc="평가 질문")
assessment_answer = dspy.OutputField(desc="예/아니오")
def metric(example, pred, trace=None):
answer, reasoning_steps = example.final_answer, pred.reasoning_steps
# 평가 질문 정의
correct = f"최종 답변이 '{answer}'와 일치하는가? (예/아니오)"
formatting = "풀이 과정이 형식을 준수하는가? (예/아니오)"
# 평가 수행
correct_result = dspy.Predict(Assess)(assessed_text=reasoning_steps, assessment_question=correct)
formatting_result = dspy.Predict(Assess)(assessed_text=reasoning_steps, assessment_question=formatting)
# 답변 저장
correct_bool, formatting_bool = [m.assessment_answer.strip() == '예' for m in [correct_result, formatting_result]]
# 두 가지 평가 기준을 모두 만족하면 2점, 아니면 0점
score = (correct_bool + formatting_bool) if correct_bool and formatting_bool else 0
if trace is not None:
return score >= 2 # 최적화 과정 : 모든 조건을 충족하는지 확인
return score / 2.0 # 평가 과정 : 0 또는 1 반환
teleprompter = BootstrapFewShot(metric=metric)
compiled_program = teleprompter.compile(GenerateAnswer(), trainset=trainset)LLM 자동 평가를 위해 Assess라는 Signature를 정의해 평가에 활용될 입출력을 정의했습니다.
평가 질문을 정의한 correct와 formatting 변수를 LLM의 입력으로 제공해 평가를 수행하고 점수를 매깁니다.
매개변수 trace로 최적화 단계와 평가 단계를 구분할 수 있습니다.
프롬프트 최적화 단계에서는 예제나 설명문을 LLM의 입력으로 제공한 응답 결과를 메트릭으로 평가하여 통과한 예제는 True, 통과하지 못한 예제는 False로 처리합니다.
trace에 해당 예제들의 실행 과정을 기록해 두고 메트릭을 통과한 예제들에 한해 trace를 활용하여 고품질 예제를 생성하고 이를 프롬프트에 포함하게 됩니다.
따라서 프롬프트 최적화를 수행하는 동안에는 trace가 None이 아니게 되어 메트릭의 반환값이 bool값이지만 평가 단계에서는 trace가 None이 되며 메트릭 반환값이 숫자가 됩니다.
이렇게 정의한 메트릭을 사용할 옵티마이저에 전달하고 compile 메서드를 호출하면 프롬프트가 최적화가 수행됩니다.
컴파일이 완료되면 검증 데이터셋을 기반으로 성능 평가를 수행하고 실제 LLM Application 개발에 활용할 수 있게 되는 거죠!
거의 다 왔습니다! 이제 프롬프트가 잘 최적화되었는지 확인하는 Evaluation 과정을 진행해 봅시다.
from dspy.evaluate import Evaluate
evaluation = Evaluate(devset=devset, metric=metric, display_progress=True, display_table=True)
eval_result = evaluation(compiled_program)
print(f"Evaluation result: {eval_result}")display_table 인자를 True로 설정하면 결과를 Pandas의 DataFrame 형식으로 확인할 수 있습니다.
검증용 데이터셋을 활용해 최적화 결과를 확인해 보고, 앞서 정의한 metric으로 성능을 수치로 확인해 보았습니다.(평가 단계에서는 trace가 None이므로 반환값이 숫자이기 때문이죠!)
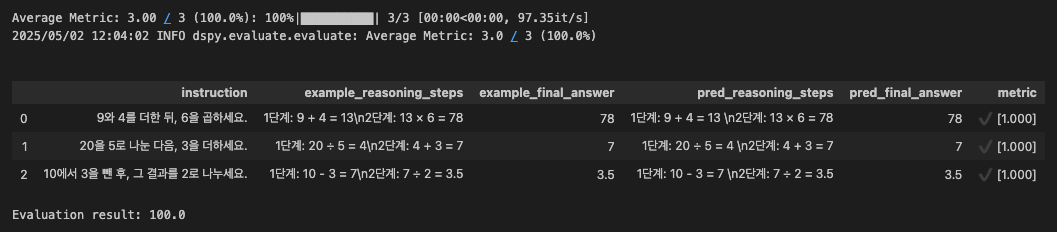
LLM이 정답을 잘 맞히고 주어진 형식을 준수하여 풀이 과정을 출력하고 있네요!
최적화와 평가를 통해 성능이 검증된 프로그램은 이제 실제 애플리케이션처럼 새로운 입력에 사용할 수 있습니다.
instruction = "(3-5)*3+1=?"
prediction = compiled_program(instruction=instruction)
print(f"Question: {instruction}", end="\n")
print(f"Reasoning: {prediction.reasoning_steps}")
print(f"Answer: {prediction.final_answer}")
# Question: (3-5)*3+1=?
# Reasoning: 1단계: 3 - 5 = -2
# 2단계: -2 * 3 = -6
# 3단계: -6 + 1 = -5
# Answer: -5새로운 질문에 대해서도 원하는 대로 정확한 답변과 형식을 갖춘 풀이 과정을 응답하는 것을 확인할 수 있습니다.
이러한 궁금증이 생기는 분들이 계실 것 같습니다. "최적화된 프롬프트를 직접 확인해 볼 수는 없나?"
결론을 먼저 말씀드리면, 확인할 수 있습니다!
기나긴 프롬프트 최적화의 여정을 지나며, 어느 정도 눈치채신 분들도 계실 것 같은데요. DSPy에서는 내부적으로 기본 세팅된 프롬프트가 있습니다.
프롬프트 최적화는 바로 이 기본 프롬프트를 수정하는 과정인 것이죠.
model.inspect_history(n=1)위 코드 한 줄이면, 마지막 LLM 모델 호출 시점의 프롬프트를 확인할 수 있습니다. System message의 지시문, User/Assistant 쌍의 Few-shot 예제, 마지막 User message의 실제 입력과 응답 결과가 제공됩니다.
System message:
Your input fields are:
1. `instruction` (str): 수학 문제에 대한 지시문
Your output fields are:
1. `reasoning` (str)
2. `reasoning_steps` (str): 풀이 과정. '1단계: 1 + 1 = 2
'와 동일한 형식으로 작성
3. `final_answer` (str): 정답
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## instruction ## ]]
{instruction}
[[ ## reasoning ## ]]
{reasoning}
[[ ## reasoning_steps ## ]]
{reasoning_steps}
[[ ## final_answer ## ]]
{final_answer}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
주어진 수학 지시문에 대해 풀이 과정을 설명하고 최종 답을 응답
User message:
This is an example of the task, though some input or output fields are not supplied.
[[ ## instruction ## ]]
5와 9를 더한 다음, 그 결과에 2를 빼세요.
Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## reasoning_steps ## ]]`, then `[[ ## final_answer ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`.
Assistant message:
[[ ## reasoning ## ]]
Not supplied for this particular example.
[[ ## reasoning_steps ## ]]
1단계: 5 + 9 = 14
2단계: 14 - 2 = 12
[[ ## final_answer ## ]]
12
[[ ## completed ## ]]
...
마치며
이렇게 DSPy를 활용하여, 지시문 형태의 수학 문제를 정확한 풀이 과정과 함께 해결하는 LLM 애플리케이션을 성공적으로 개발했습니다. 이 과정에서 DSPy의 강력한 장점인 프롬프트 자동 최적화 기능 덕분에, 프롬프트 엔지니어링에 많은 시간을 들이지 않고도 원하는 성능을 달성할 수 있었습니다.
이 글이 여러분만의 LLM 애플리케이션 개발 여정에 든든한 길잡이가 되기를 바라며, 이만 포스팅을 마치겠습니다.
읽어주셔서 감사합니다!
References
DSPy를 사용한 LLM 최적화: AI 시스템 구축, 최적화 및 평가를 위한 단계별 가이드
DSPy가 체계적인 언어 모델 최적화를 통해 AI 프로젝트를 어떻게 변화시킬 수 있는지 알아보세요. DSPy를 사용하여 강력한 AI 시스템을 구축, 최적화 및 평가하는 방법을 단계별로 알아보세요. AI 워
www.unite.ai
DSPy
The framework for programming—rather than prompting—language models.
dspy.ai
https://github.com/stanfordnlp/dspy
GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—language models
DSPy: The framework for programming—not prompting—language models - stanfordnlp/dspy
github.com
'Tech' 카테고리의 다른 글
| AWS Backup 서비스를 통한 EC2 백업 체계 개선 (0) | 2025.05.27 |
|---|---|
| LLM을 이용한 여행 컨시어지 만들기 (0) | 2025.03.10 |
| AI 아이콘에 생명을 불어넣다_케이뱅크 아이콘 AI 연습기 2편 (0) | 2024.12.23 |
| 아이콘이 아이콘을 낳는다?_케이뱅크 아이콘 AI 연습기 1편 (2) | 2024.12.20 |
| aws re:Invent 2024 참가자를 위한 (뒤늦은) 2023 참관기/팁 방출 (20) | 2024.10.08 |